Jupyter初探
Jupyter notebook安装
安装了Anaconda发行版时已经自动安装了Jupyter Notebook
直接打开命令窗口,输入jupyter notebook启动jupyter notebook
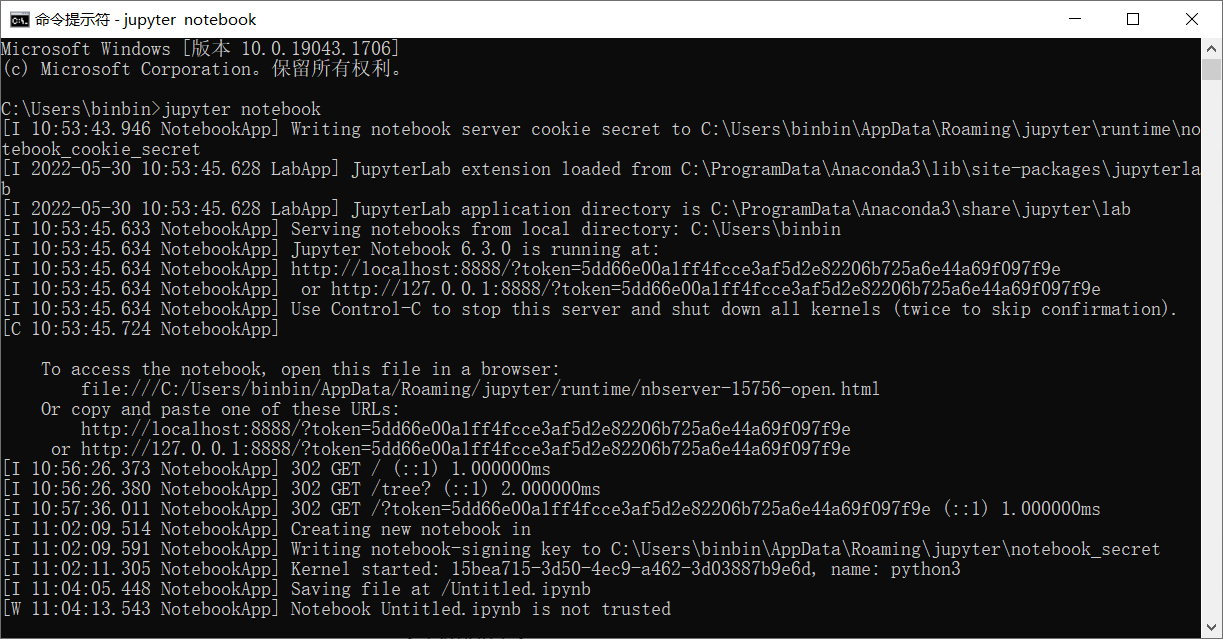
在浏览器输入url即可进入jupyter
这些所列的文件目录都存放在直接打开cmd时的初始目录下
设置Jupyter Notebook文件存放位置
创建配置文件
|
|

修改配置文件
搜索c.NotebookApp.notebook_dir,设置文件的默认存储位置

启动时出现的问题:
[W 14:06:44.163 NotebookApp] 404 GET /api/kernels/39fc6aa7-5b95-4bc9-b561-b524370dbcd4/channels?session_id=0794ad0158734a7096f06b73e6d8cfd2 (127.0.0.1): Kernel does not exist: 39fc6aa7-5b95-4bc9-b561-b524370dbcd4
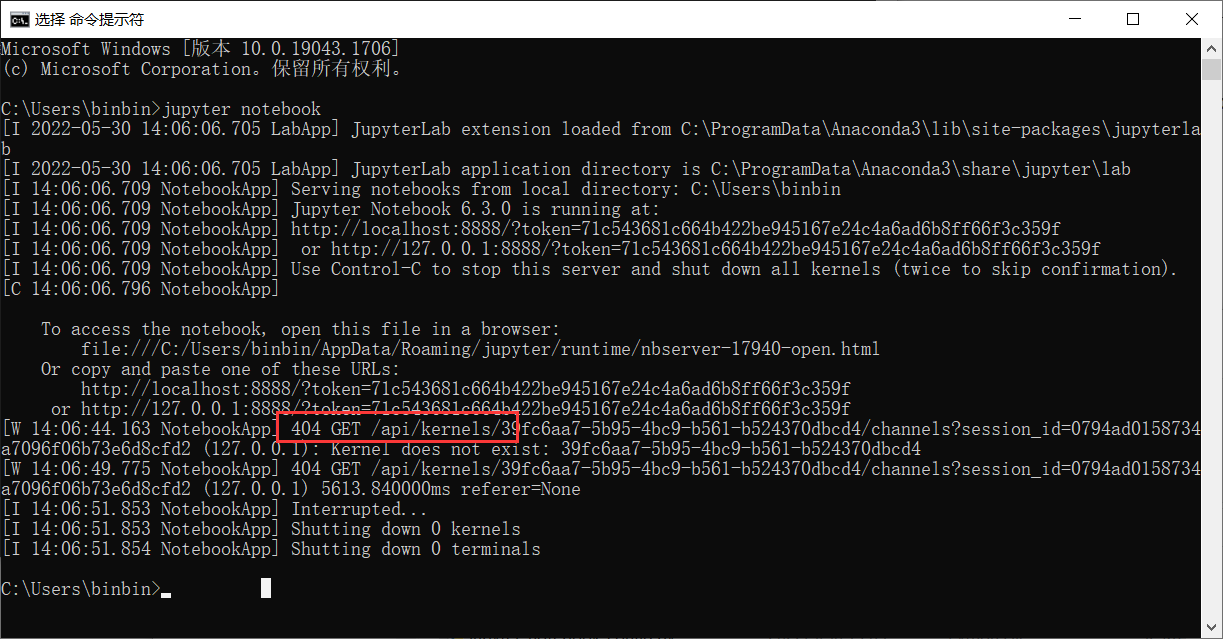
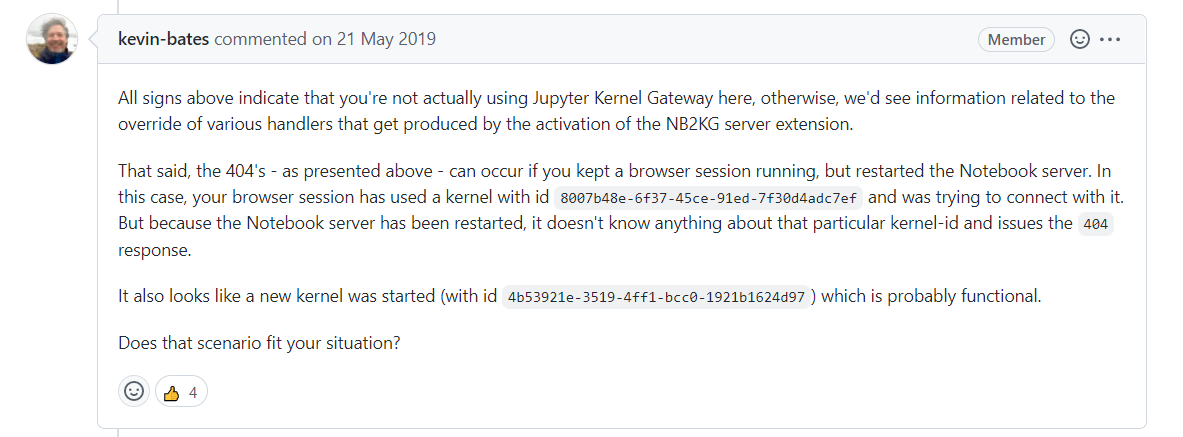
解决方案:
|
|
保存和检查点(checkpoint)
在开始前,要记得定时保存文件,这可以直接采用快捷键 Ctrl + S 保存文件,它是通过一个命令–“保存和检查点”实现的,那么什么是检查点呢?
每次创建一个新的 notebook,同时也创建了一个 checkpoint 文件,它保存在一个隐藏的子文件夹 .ipynb_checkpoints 中,并且也是一个 .ipynb 文件。默认 Jupyter 会每隔 120 秒自动保存 notebook 的内容到 checkpoint 文件中,而当你手动保存的时候,也会更新 notebook 和 checkpoint 文件。这个文件可以在因为意外原因关闭 notebook 后恢复你未保存的内容,可以在菜单中 File->Revert to Checkpoint 中恢复。
拓展功能
关联jupyter与conda环境
有两种方式关联
nb_conda
关联Jupyter Notebook和conda的环境和包——“nb_conda”
① 安装
|
|
② 使用
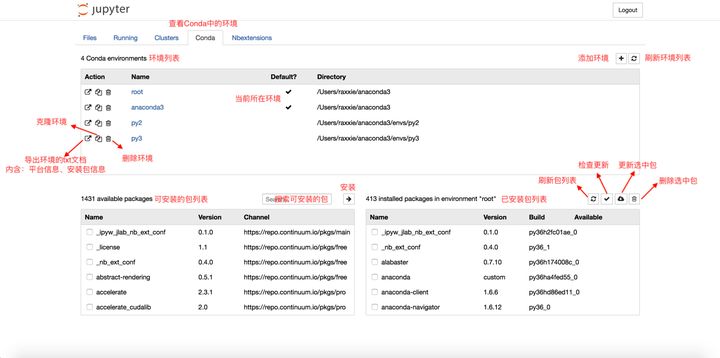
可以在Conda类目下对conda环境和包进行一系列操作。
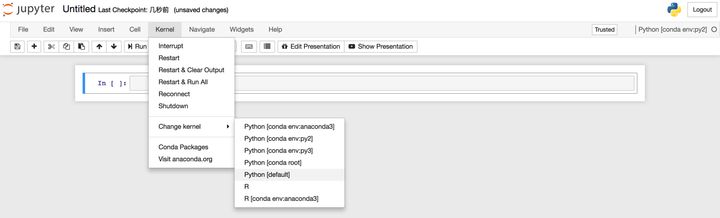
可以在笔记本内的“Kernel”类目里的“Change kernel”切换内核。
③ 卸载
|
|
执行上述命令即可卸载nb_conda包。
Jupyter notebook怎么使用自己新建的conda环境
以下操作都在命令行中操作:
|
|
tensorflow_study是我新建环境的名字,你的环境名字自己根据情况取;python版本也根据自己的需求来选择。
|
|
进入新建的环境
|
|
安装nb_conda是为了实现不同环境的切换与选择。
|
|
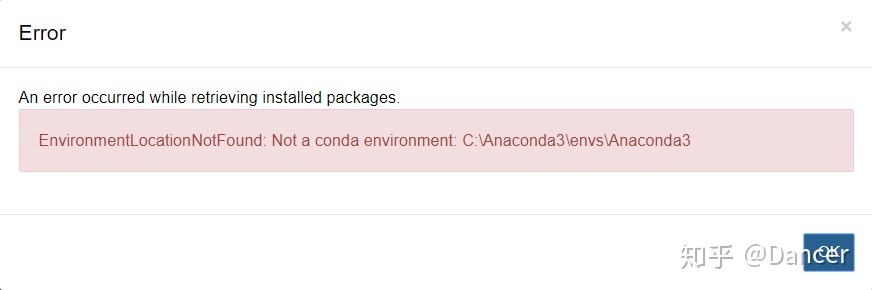
==错误1:EnvironmentLocationNotFound: Not a conda environment==
打开jupyter后点击Conda会弹出这样的错误:
解决方法:
找到Anaconda安装路径下nb_conda库的envmanager.py文件
win系统在目录:Anaconda3\Lib\site-packages\nb_conda\envmanager.py
linux系统在目录:Anaconda3/pkgs/nb_conda-2.2.1-py36_0/lib/python3.6/site-packages/nb_conda/envmanager.py
找到该文件后在83~86行有这样一段代码:
|
|
我们将此段代码改成如下:
|
|
然后重启jupyter就可以了。
==错误2:可使用的环境没有我新创建的jupyter环境==
==nb_conda 要装到你的虚拟环境中才会在jupyter notebook中显示!!!!!!==
如何在 Jupyter Notebook 中切换/使用 conda 虚拟环境
使用 nb_conda_kernels 添加所有环境
这个方法就是一键添加所有 conda 环境
|
|
注意:这里的 conda install nb_conda_kernels 是在 base 环境下操作的。
安装好后,打开 jupyter notebook 就会显示所有的 conda 环境啦,点击随意切换。
ipykernel
1、直接在新建一个环境的同时,给该环境安装ipykernel
|
|
2、激活虚拟环境
|
|
3、将该环境写入jupyter的kernel中
|
|
4、进入jupyter 服务器
|
|
安装插件
首先安装扩展库
|
|
-c conda-forge是指明在库conda-forge中下载jupyter_contrib_nbextensions
1.Markdown生成目录
不同于有道云笔记的Markdown编译器,Jupyter Notebook无法为Markdown文档通过特定语法添加目录,因此需要通过安装扩展来实现目录的添加。
|
|
-c conda-forge是指明在库conda-forge中下载jupyter_contrib_nbextensions
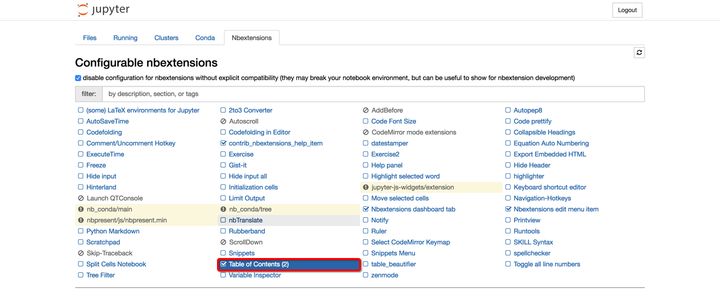
执行上述命令后,启动Jupyter Notebook,你会发现导航栏多了“Nbextensions”的类目,点击“Nbextensions”,勾选“Table of Contents ⑵”
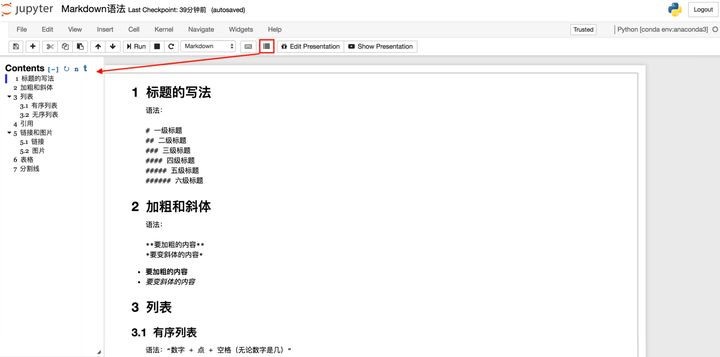
之后再在Jupyter Notebook中使用Markdown,点击下图的图标即可使用啦。
==遇到的问题:==
插件不显示
解决方法:
jupyter nbextensions configurator不显示插件
再执行如下命令
|
|
2.代码自动补全扩展
勾选 Hinterland
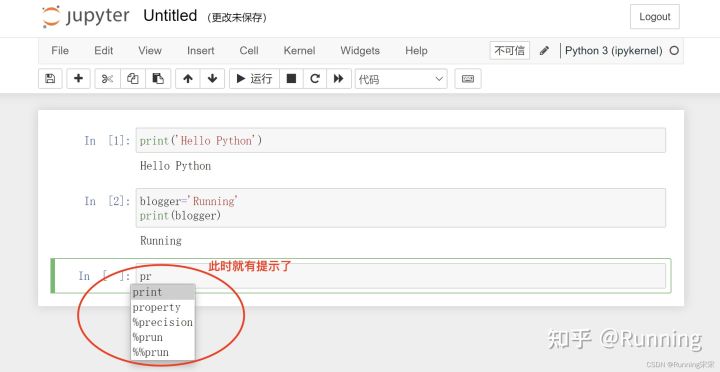
安装插件后出现警告“Config option template_path not recognized by LenvsLatexExporter”
原因是nbconvert6.0.0版本以上的某些参数的名称发生了更改,与原先版本不兼容,需要将版本降低到5.6.1
|
|
jupyter代码自动补全插件、安装后出现警告“Config option template_path not recognized by LenvsLatexExporter”的解决方案
3.主题
4.Autopep8
这是一个将代码按照PEP8进行格式化的插件,前提是需要通过pip install autopep8安装autopep8,安装完之后需要重启jupyter notebook服务才能生效。同样在Nbextention选项卡中勾选Autopep8,在工具栏中会多一个“锤子”一样的按钮,可以帮助我们排版代码,使其符合pep8标准。
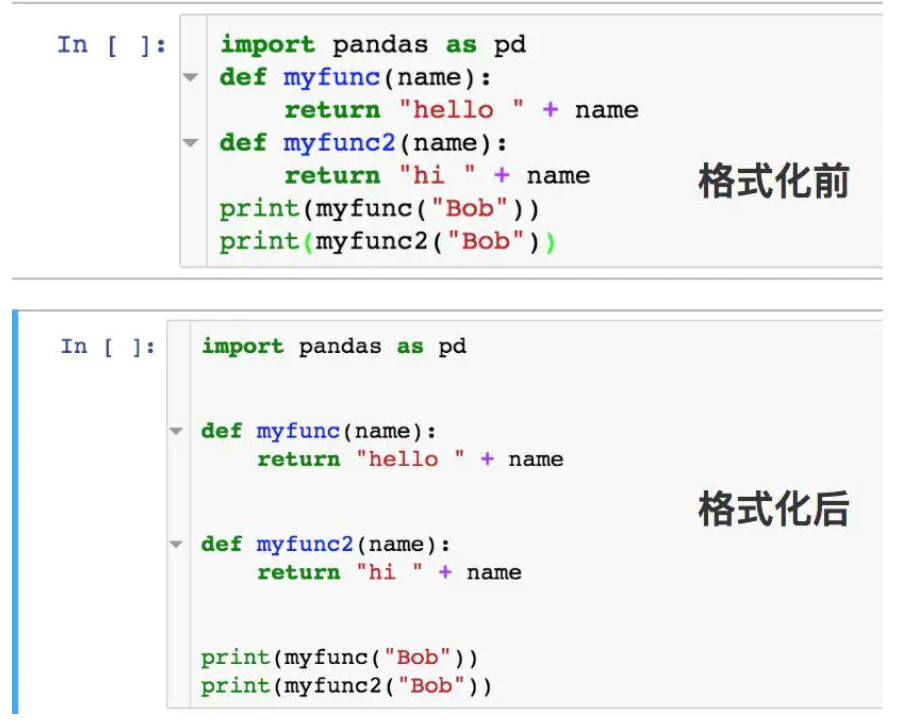
5.Variable inspector
该插件可以帮助我们查看当前notebook中所有的变量的名称,类型,大小和值。省去了df.shape,type()等语句的执行,也代替了前文提到的魔法函数“%whos”的执行,读者可以自行尝试一下。
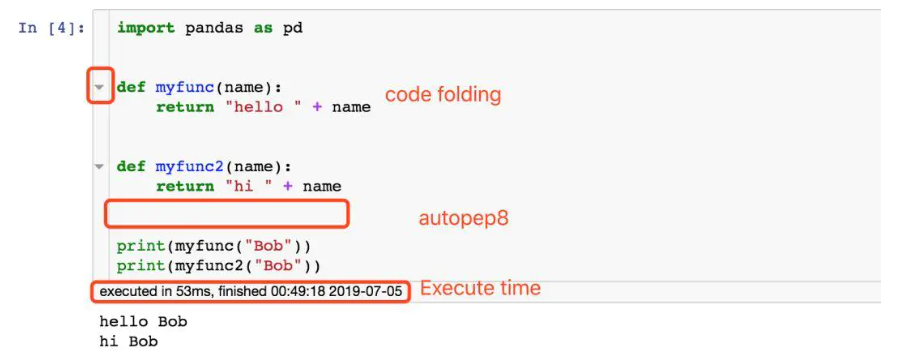
6.Code folding
顾名思义,该插件可以对代码进行一定的折叠,例如遇到class,def等关键字,而且主体代码又很长时,折叠代码会方便阅读,这一点也让jupyter notebook更像一个IDE。
7.Execute time
该插件可以显示每一个cell中代码的执行时间。
除此之外还有一些其他常见的插件扩展,例如Notify,Collapsible headings等,读者可以自行探索查看,并配置使用。
Jupyter快捷键
加载指定网页源代码
|
|
其中,URL为指定网站的地址。
加载本地Python文件
|
|
注意
- Python文件的后缀为“.py”。
- “%load”后跟的是Python文件的绝对路径。
- 输入命令后,可以按
CTRL 回车来执行命令。第一次执行,是将本地的Python文件内容加载到单元格内。此时,Jupyter Notebook会自动将“%load”命令注释掉(即在前边加井号“#”),以便在执行已加载的文件代码时不重复执行该命令;第二次执行,则是执行已加载文件的代码。
直接运行本地Python文件
执行命令:
|
|
或
|
|
或
|
|
注意
- Python文件的后缀为“.py”。
- “%run”后跟的是Python文件的绝对路径。
- “!python3”用于执行Python 3.x版本的代码。
- “!python”用于执行Python 2.x版本的代码。
- “!python3”和“!python”属于
!shell命令语法的使用,即在Jupyter Notebook中执行shell命令的语法。 - 输入命令后,可以按
control return来执行命令,执行过程中将不显示本地Python文件的内容,直接显示运行结果。
在Jupyter Notebook使用shell命令
① 方法一——在笔记本的单元格中
⑴ 语法
|
|
- 在Jupyter Notebook中的笔记本单元格中用英文感叹号“!”后接shell命令即可执行shell命令。
|
|
② 方法二——在Jupyter Notebook中新建终端
⑴ 启动方法
在Jupyter Notebook主界面,即“File”界面中点击“New”;在“New”下拉框中点击“Terminal”即新建了终端。此时终端位置是在你的home目录,可以通过pwd命令查询当前所在位置的绝对路径。
⑵ 关闭方法
在Jupyter Notebook的“Running”界面中的“Terminals”类目中可以看到正在运行的终端,点击后边的“Shutdown”即可关闭终端。
JupyterLab
JupyterLab最全详解,如果你还在使用Notebook,那你就out了!
Jupyter Notebook是一个交互式笔记本,支持运行 40 多种编程语言。Jupyter Notebook 的本质是一个 Web 应用程序,便于创建和共享文学化程序文档,支持实时代码、数学方程、可视化和 markdown,用途包括:数据清理和转换,数值模拟,统计建模,机器学习等等 。
JupyterLab是Jupyter主打的最新数据科学生产工具,在一定程度上是为了取代Jupyter Notebook。它支持安装插件以及有着更好的界面。而 JupyterHub是为多个用户提供Jupyter Notebook的最佳方式。
Jupyter NoteBook / JupyterLab / JupyterHub 区别与关系简介
搭建环境方案(根据需求调整):
- 线上环境:The Littlest JupyterHub + JupyterLab
- 开发环境:JupyterHub + JupyterLab
Tips
当前版本的 Jupyter Lab 网页版可视化界面虽然用起来很方便,但是也存在很多问题,==目前最好的解决方法是尽量将对 Jupyter Lab 有改动的操作自己在 Anaconda Prompt 下进行==,最主要的原因就是==即使发生了问题,也可以从Prompt中直观的看到错误原因甚至解释==。这对于解决问题其实是至关重要的一环。
安装
|
|
在命令行使用jupyter-lab或jupyter lab命令运行Jupyter lab
作为官方宣传的jupyter lab3.0版本后最大的改变,似乎我们可以不需要nodejs,不通过jupyter labextension install语句,仅仅依靠pip/conda/mamba就可以安装拓展
|
|
Jupyter Lab配置
使用命令创建配置文件,其会生成C:\Users\用户名\.jupyter\jupyter_notebook_config.py或者/home/用户名/.jupyter/jupyter_notebook_config.py
|
|
控制台出现的各种警告
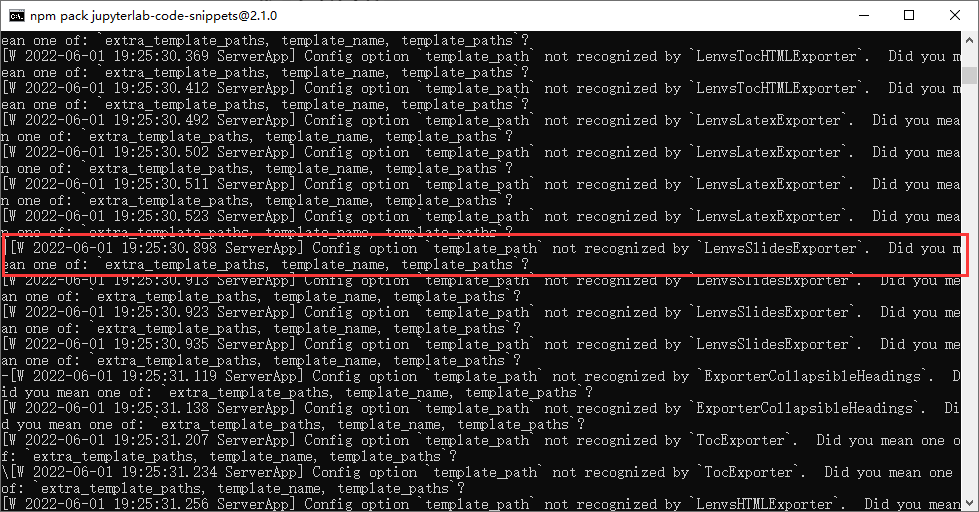
安装插件后出现警告“Config option template_path not recognized by LenvsLatexExporter”
原因是nbconvert6.0.0版本以上的某些参数的名称发生了更改,与原先版本不兼容,需要将版本降低到5.6.1
|
|
ClobberError: This transaction has incompatible packages 或者The package ‘xxx‘ cannot be installed due==(未解决)==
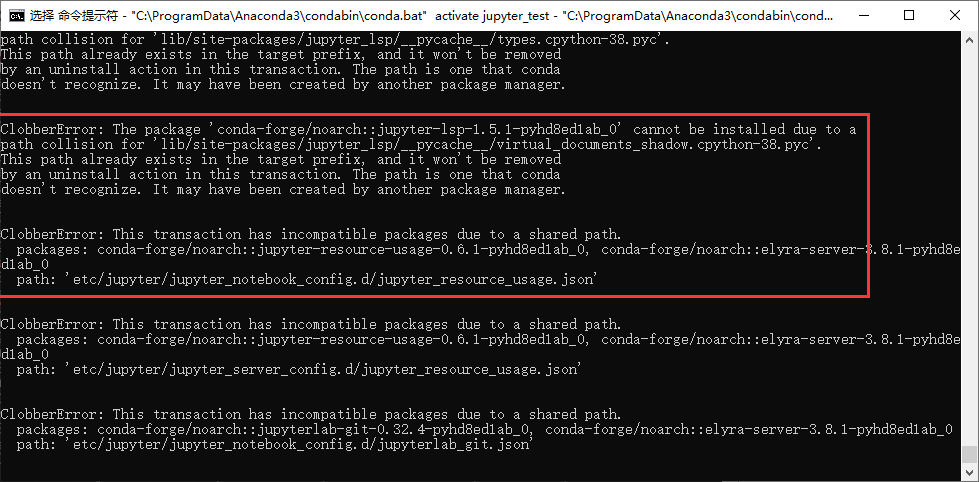
原因:conda和pip等相关包的版本太低,自动更新不能用。 解决方案:在命令行中输入以下命令:==(没效果)==
|
|
Failed validating ‘additionalProperties’ in schema:==(未解决)==
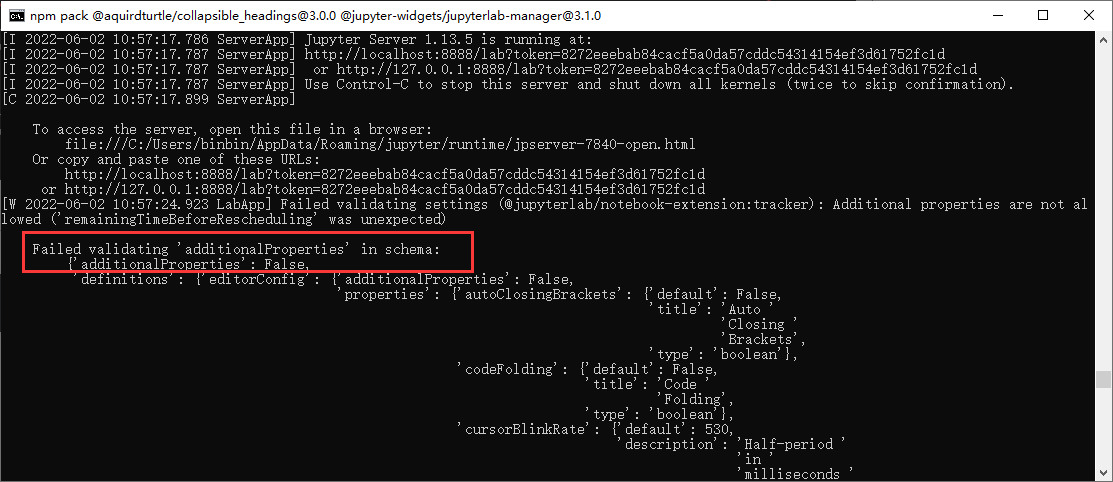
WARNING | Config option kernel_spec_manager_class not recognized by LabBuildApp==(未解决)==
如果出现

可以先更新pip
|
|
插件

==nodejs版本不能过低==
同时!!
==外部的node环境好像不生效,要在conda环境中装node==
在anaconda prompt中运行下面的语句安装nodejs:
conda install -c conda-forge nodejs<15
其次需要注意的一点是:nodejs最好选择14.x.x版本,如果选择了16.x.x可能会遇到各种奇葩问题 。(这是个大坑)
还有,建议用官方默认源来下载npm资源,yarn同理。别用taobao的源。
taobao的源有些不对,也会导致资源下载不成功。而且taobao在2022年5月要改域名了。
1.jupyterlab-code-snippets(没安装成功)
|
|
报错:

==外部的node环境好像不生效,要在conda环境中装node==
==遇到的问题:==
安装之后无法使用
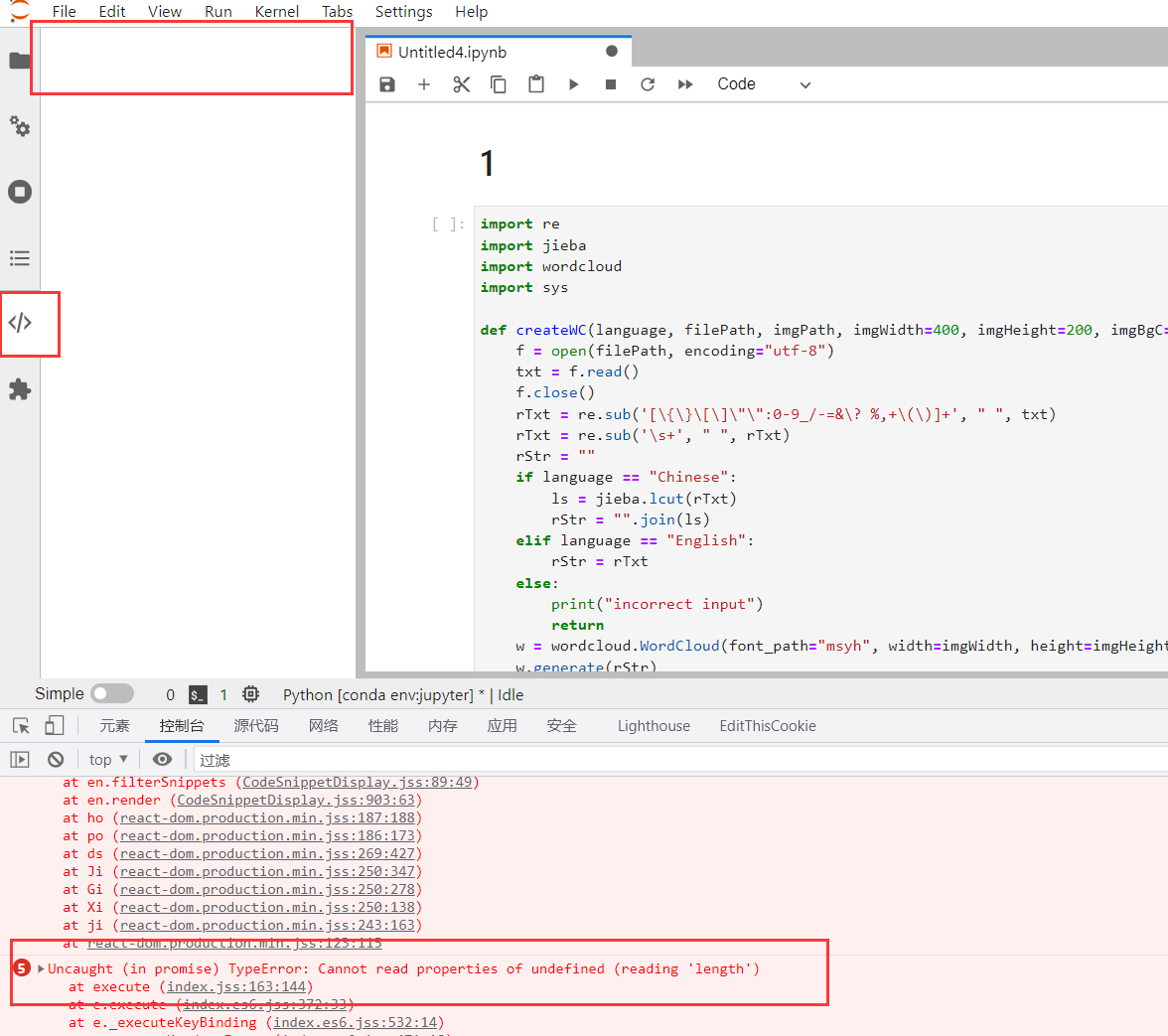
解决方法:
elyra-code-snippet-extension(安装成功)
|
|
如果出现
可以先更新pip
|
|
|
|
👆命令装不了
==控制台安装出错==
==页面安装出错==
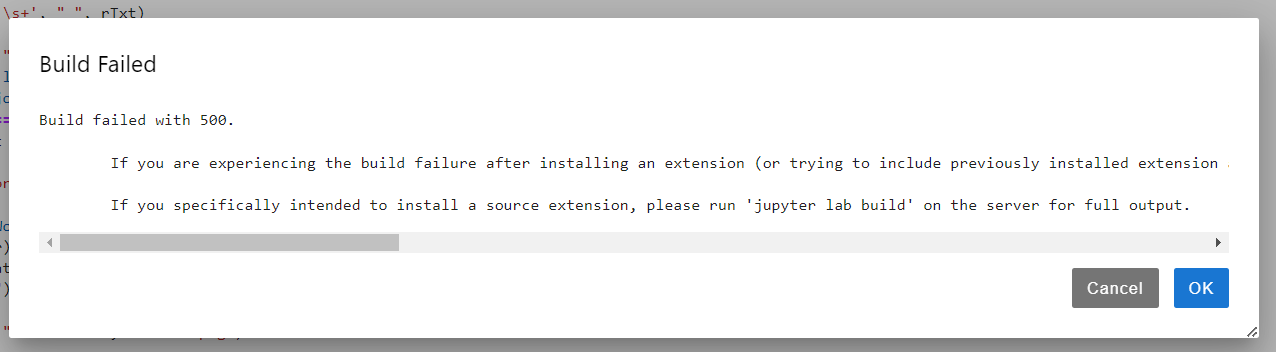
code snippets存储路径:$JUPYTER_DATA_DIR/metadata/code-snippets
|
|


2.jupyter lsp(安装成功)
jupyter lab 代码提示 代码补全插件 jupyter lsp 配置教程 :Hinterland mode
1.安装JupyterLab-lsp
|
|
2.安装python-lsp-server
|
|
3.安装frontend extension
|
|
3.或者启动 jupyter lab,在插件中搜索lsp,点击@krassowski/jupyterlab-lsp下的install安装
4.点击OK
5.重新进入jupyter lab,输入代码时按tab键,就可以使用代码提示啦 。
若想实现jupyter notebook中类似Hinterland mode的自动提示,还需进行下面的设置
6.依次点击Settings–>Advanced Settings Editor
7.选择Code Completion,在右侧输入如下代码,并保存,即可开启Hinterland mode
|
|
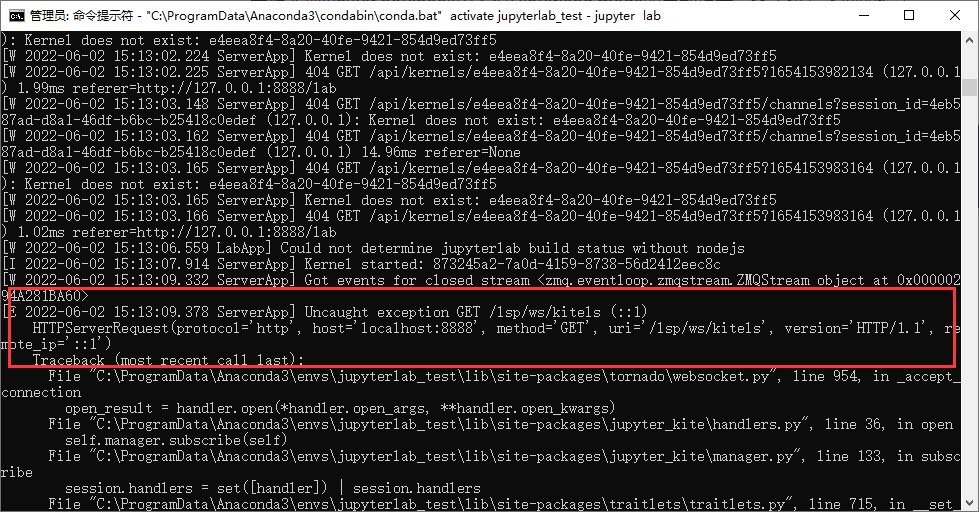
==可能会出现如下问题:==
3.ipywidgets(安装成功)
生成控件(下拉菜单, 滑条等等), 非常方便手动调参, 因为会即使反馈, 根据反馈不断调整参数
先用pip安装ipywidgets: pip install ipywidgets
用这个命令(指定为版本7):pip install ipywidgets==7
这样安装会出现如下问题:
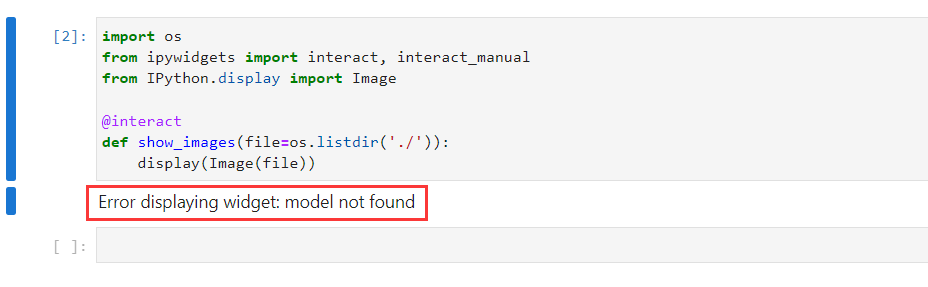
**解决方法(这个方法没解决):**https://www.coder.work/article/3135992
ipywidget 7.5 破坏了 jupyter lab,它也影响了其他库。
https://github.com/plotly/plotly.py/issues/1659
降级到 7 解决
安装完成后在Jupyter Notebook中激活:
|
|
如果使用Jupyterlab,运行以下代码:
|
|
在Notebook中导入并使用ipywidgets:
|
|
交互式控件入门
假设我们有一个数据框(dataframe),包含Medium文章的统计信息:
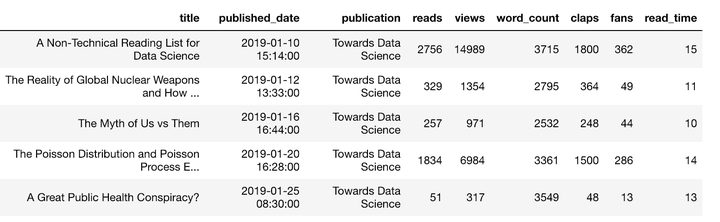
如何查看总阅读次数超过1000的文章?
|
|
如果要显示点赞超过500的文章,必须编写一行新的代码:
|
|
如果不用编写更多代码就可以快速更改这些参数,那不是很好吗?尝试ipywidgets:
|
|
4.jupyterlab_variableinspector(安装成功)
jupyterlab-variableInspector帮助我们在jupyter lab中查看当前环境中存在的变量相关信息,以美观的界面形式对多种类型的对象予以呈现
|
|
如果遇到Solving environment: failed with initial frozen solve. Retrying with flexible solve.参考下面这个博客
https://blog.csdn.net/Sakura_Logic/article/details/108312146
👇方式安装失败
|
|
==这个插件build会失败==
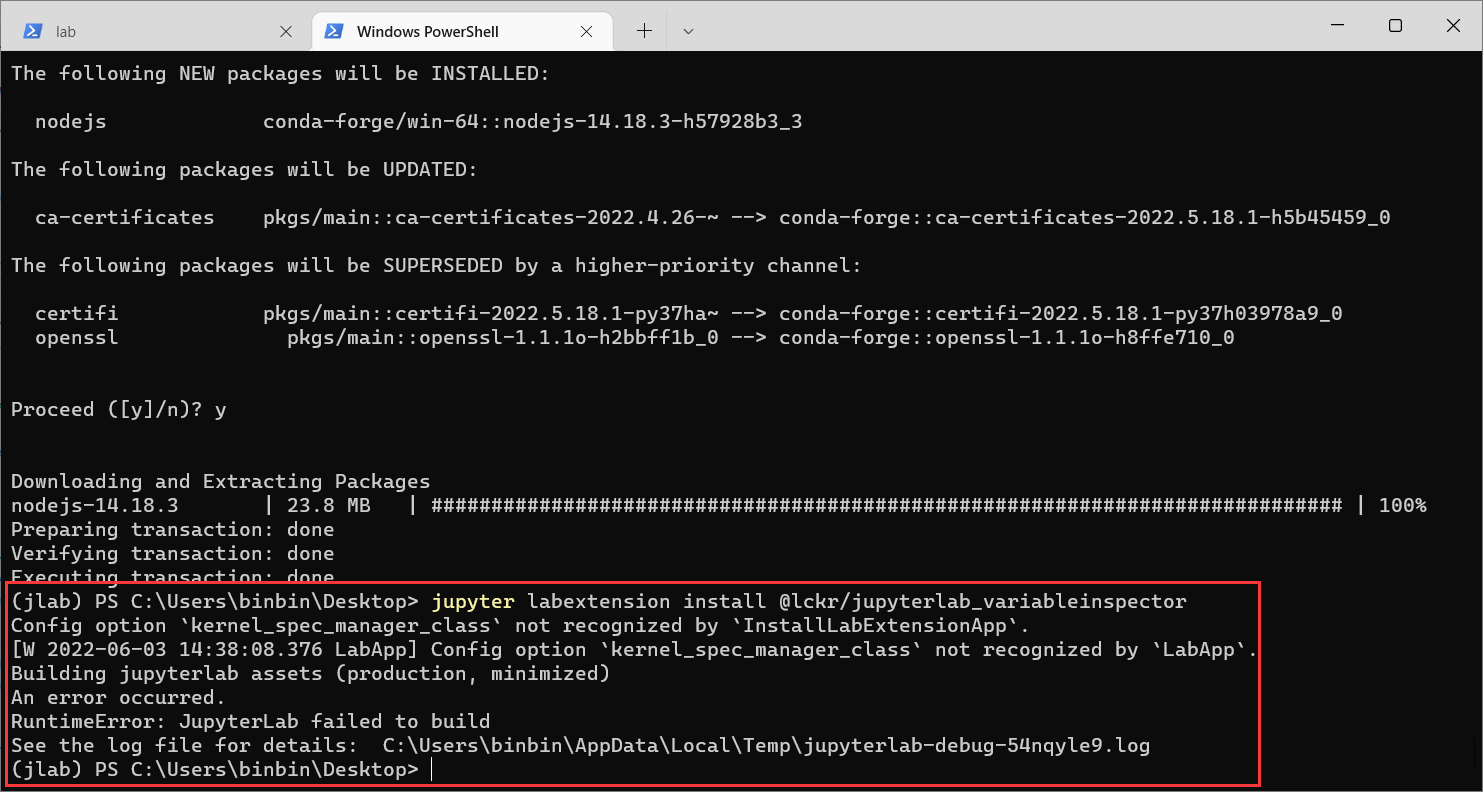
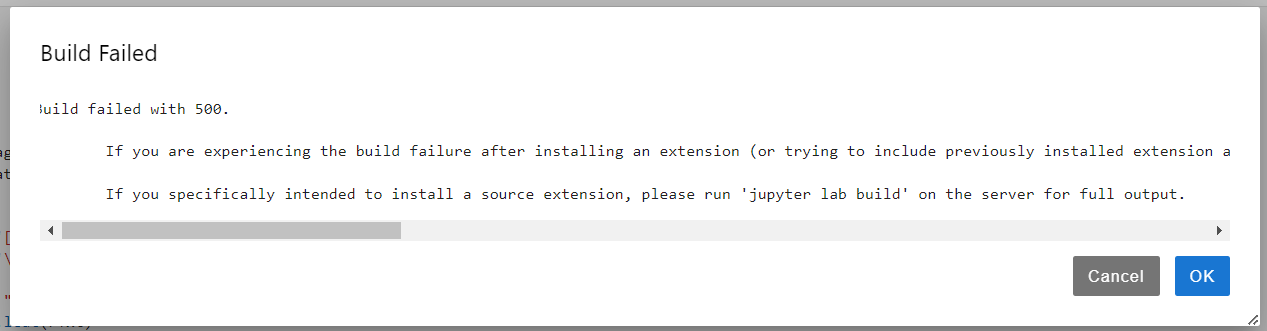
5.代码折叠
设置如下:codeFolding:true,即可见代码折叠

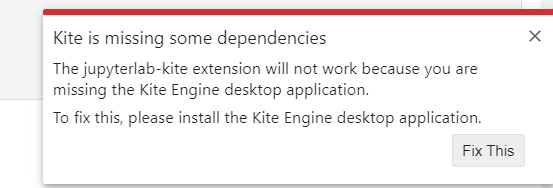
6.kite(没安装成功)
kite插件是能够对代码块进行自动补充和对函数参数进行解释的插件。
|
|
安装出错:缺少对应的wheel
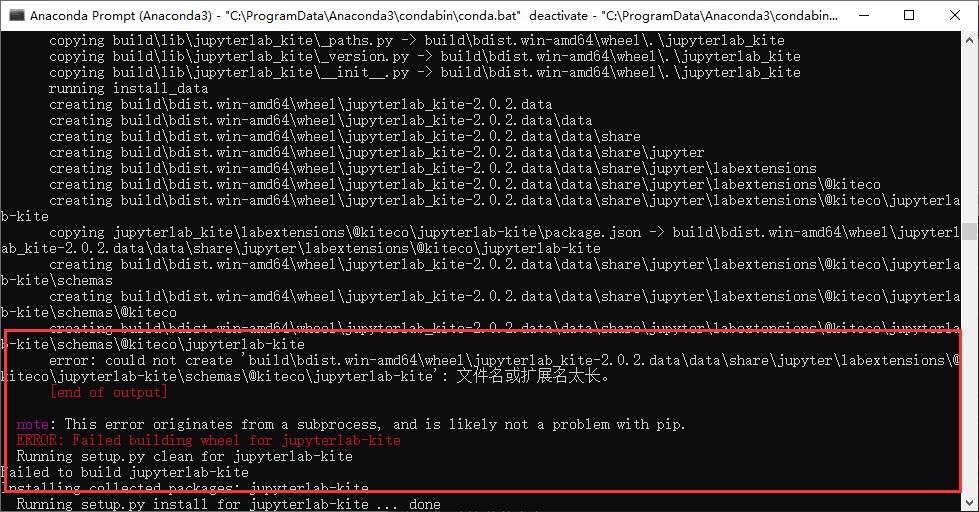
启动时出错
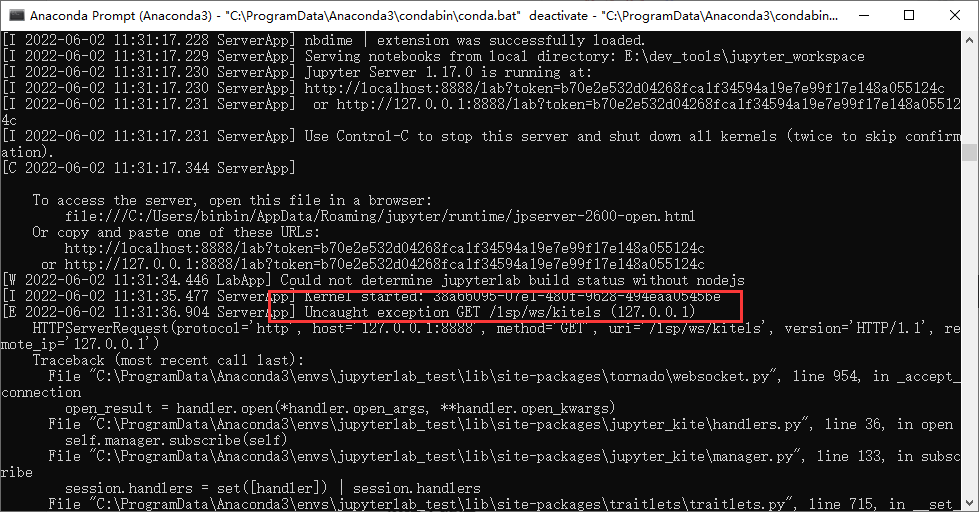
7.elyra(未安装)
搭建工作流
8.jupyterlab_code_formatter(安装成功)
|
|
或使用jupyter页面安装
如果python版本过高会无法使用
**解决方法:**运行jupyter server extension enable --py jupyterlab_code_formatter并重启jupyter lab
JupyterHub
JupyterHub有两种部署方式:
When to use The Littlest JupyterHub

安装
安装教程:
1.安装miniconda
https://www.jianshu.com/p/47ed480daccc
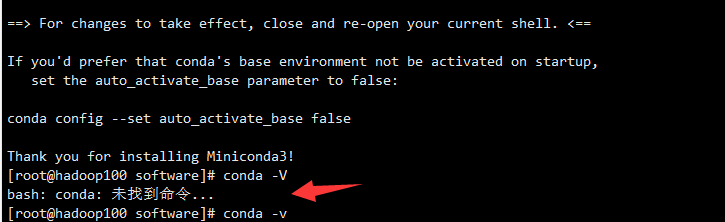
解决方案:
打开一个终端,然后输入命令行打开bashrc文件:
|
|
注意这里要有sudo,不然无法编辑里面的内容。
打开自己的安装目录/opt/software/miniconda3/bin,输入指令pwd查看路径。
在bashrc文件中输入:
|
|
保存关闭bashrc文件,在命令行输入:
|
|
随后检测一下:
|
|
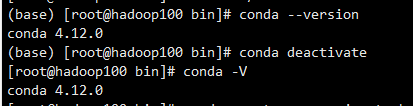
如上图所示,成功。
2.安装JupyterHub
pip, npm:
|
|
建立软连接
|
|
conda (one command installs jupyterhub and proxy):
|
|
测试是否安装成功
|
|
3.启动jupyterhub
命令行输入
|
|
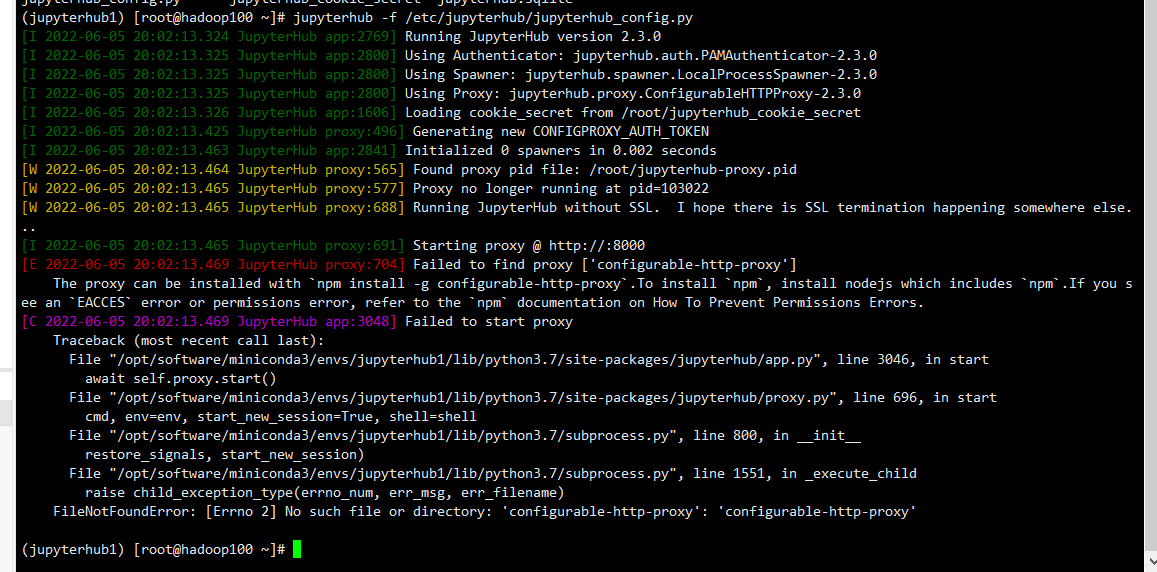
浏览器输入http://localhost:8000(localhost可换成服务器ip),通过服务器的用户登录(非root,root默认是无法登录的)

==遇到的问题:==
使用pip安装启动jupyterhub时,找不到 ‘configurable-http-proxy’
建立软连接
|
|
多用户需求
[Centos/Jupyterhub] 多用户远程登录 Jupyter 详细配置
Authentication and User Basics
安装 JupyterHub 踩坑指南 —— 如何通过 JupyterHub 实现多用户管理
默认情况下,要真正的实现分配用户账号,需要满足以下两点要求:
- c.Authenticator.whitelist 指定了用户名
- 在系统中创建了该用户(adduser / useradd)
tips: 默认情况下,密码为系统中该用户对应的密码
JupyterHub支持多种Spawner,可以启动LocalProcess(默认)的JupyterLab,docker容器版的JupyterLab,也可以启动Kubernetes(k8s)集群Pod版的JupyterLab、Hadoop Yarn上的JupyterLab等等。
针对测试或者自己单用户使用,默认的LocalProcess就可以;若多用户不是很多,隔离性也没那么高要求的,LocalProcess也能满足;如果有意向大量不确定用户提供,还是使用docker容器或者k8s版本的比较好,隔离性好,也能限制资源用量。
新增用户
每个用户的环境都是独立的
pip install都是安装在 /home/用户/.local/lib/python3.7/site-packages/下
登录
==登录时遇到的问题:==
登录普通用户的时候日志报错
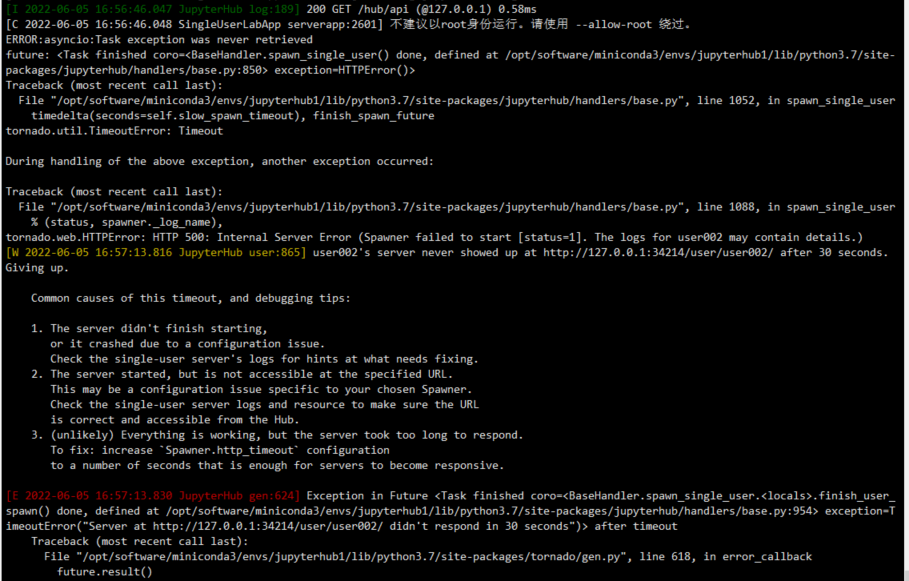
在输入node -v 时显示未找到命令,而且 configurable-http-proxy 也没了
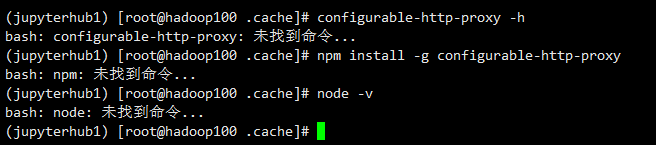
软连接失效
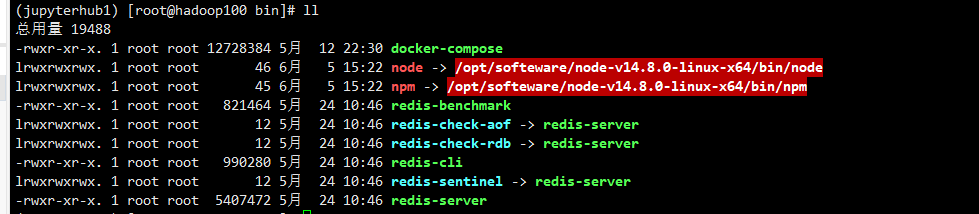
删除软连接,新建软连接,==手动输入==
==解决方法:新建一个环境!!!重复上述操作==
配置文件设置
生成配置文件
|
|
这个命令会在你的当前目录下生成一个jupyterhub_config.py文件,接下来我们需要在这个文件中配置我们的网络和用户管理。(建议放在编撰的UNIX文件系统位置:/etc/jupyterhub)
|
|
上述命令可以根据你的配置文件启动jupyterhub。
在存放jupyterhub_config.py的文件夹下执行jupyterhub启动服务
配置 jupyterhub_config.py
|
|
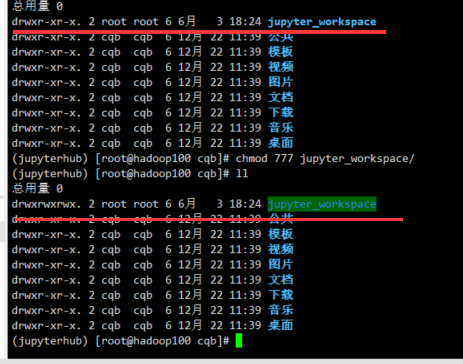
c.Spawner.notebook_dir设置之后新建工程出现Permission denied: 未命名.ipynb
==解决方法:==
修改该文件夹的权限:chmod 777 jupyter_workspace/
|
|
|
|
设置管理员,管理员能够查看和启停所有用户的servers
|
|
设置普通用户,管理员用户不需要加入白名单
|
|
注意事项
==须在root管理员下启动jupyterhub,才可以实现多用户(否则会出现权限不足和有些用户无法登录的情况)==;
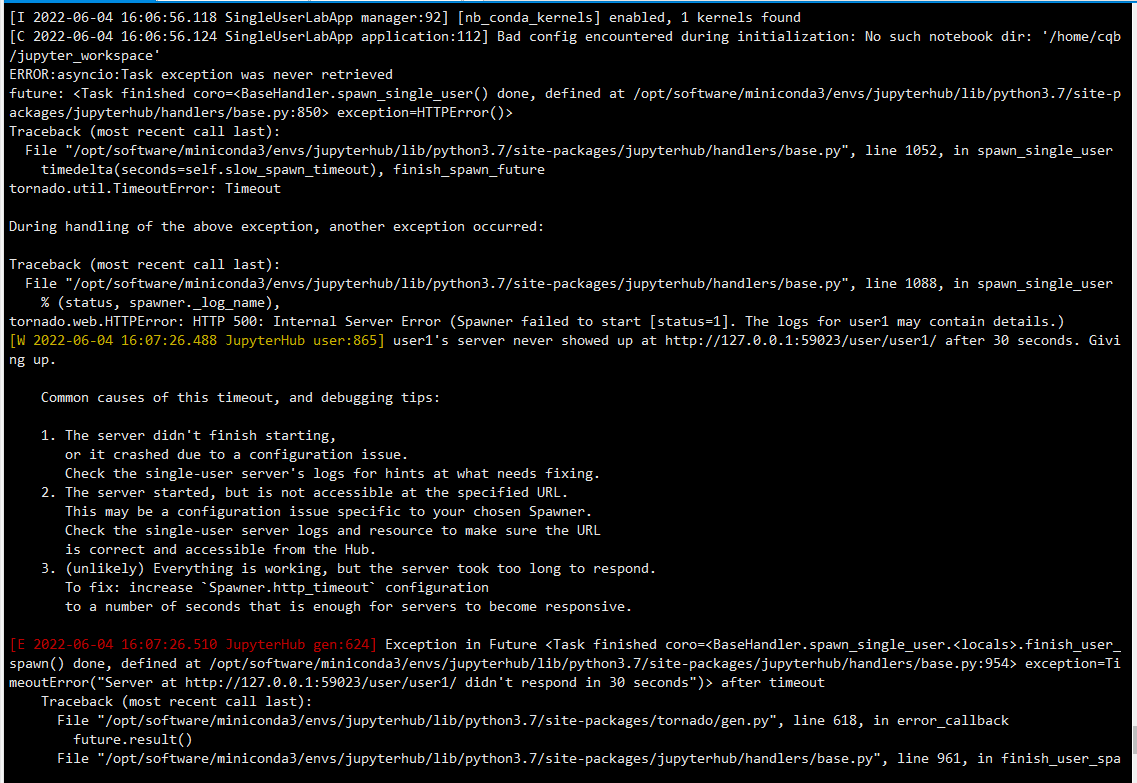
==user1登录失败==
没有权限访问jupyter_workspace文件夹 No such notebook dir: '/home/cqb/jupyter_workspace'
工作空间配置
工作空间分为共享工作空间(多用户共用一个文件夹)或者是用户独享工作空间
共享工作空间
共享的话要配置 Linux多用户共同使用同一目录
https://blog.csdn.net/catscanner/article/details/105129846
例如有alex,bob两个用户,互相无法访问对方的home~文件夹,为了共享文件,可以让root用户在/home中创建一个shared文件夹,然后创建一个用户组dev01
在root或者sudo下:
|
|
创建用户组之后添加文件夹并为文件夹更改组
|
|
接下来更改文件夹权限,使得owner以及用户组可以访问,+s是为了确保之后添加进去的文件夹也继承同样的权限
|
|
然后将需要共享文件的用户添加到dev01这个用户组
|
|
注意,使用root环境运行su - , 而不是root权限su
至此,两人都可以访问/home/dev_shared文件夹了
另外,用户可以自行检查自己所在的用户组
|
|
如果是全新的账户,root用户可以先建立新用户:
|
|
使用root权限查看所有的group情况
|
|
独享工作空间
独享的话配置文件设置 c.Spawner.notebook_dir = '~/jupyter_workspace' 每个用户的文件会放在/home/user/jupyter_workspace下
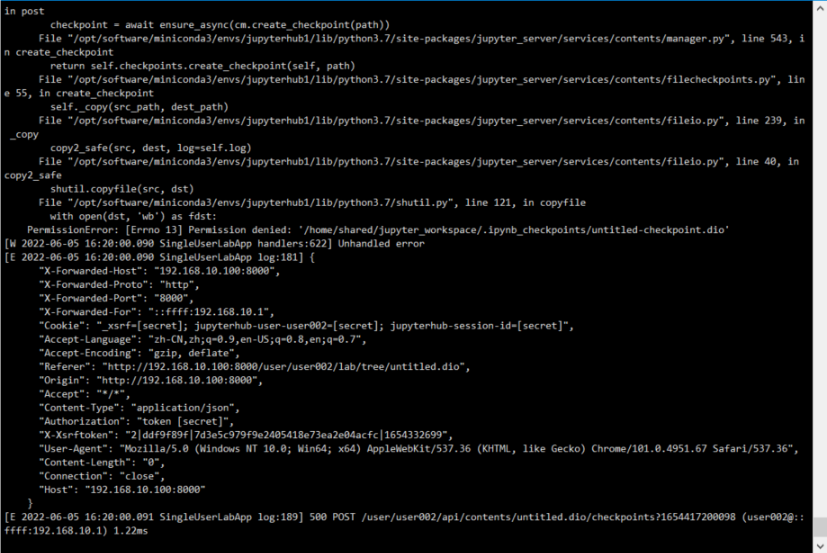
==遇到的问题:==
创建文件的时候报错Permission denied: '/home/shared/jupyter_workspace/.ipynb_checkpoints/untitled-checkpoint.dio'
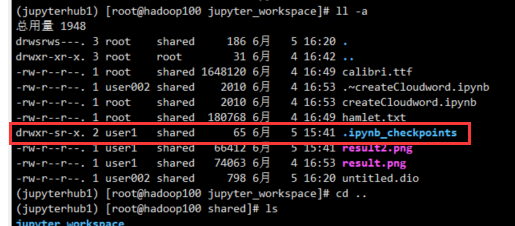
.ipynb_checkpoint文件夹没有写权限,注意这个文件夹是 user1 创建的,其他用户没有写权限,所以==用户共享一个工作空间的方案不可行==
解决方法:
|
|
注意:
其他用户创建的文件是无法保存的(既然这样子,那其实就没有必要让用户共享工作空间,因为文件并不能被修改,可以用户拥有自己的工作空间,同时创建一个共享文件夹,用户将需要共享的文件放到该共享文件夹让对方调用)

用户安装插件
只能使用 pip install 安装
用户登录的时候通过pip install都是安装在 /home/用户/.local/lib/python3.7/site-packages/下的,各用户的环境都是隔离的
因为只允许非root用户登录
无法通过conda install安装,因为安装目录是在 /opt/software/miniconda3/envs/jupyterhub1 ,用户无写权限

同样的,插件在web界面也是无法进行安装的(conda install无权限)

若是允许用户安装插件,可将插件安装所在文件夹共享出来,指定特定的组权限可写
|
|
==遇到的问题:==
文件权限设置完成后,通过命令安装插件
|
|
==输入上面这个命令之后jupyterhub就启动不起来了!!!****==
node:error while loading shared libraries: libnode.so.83
error while loading shared libraries的解決方法
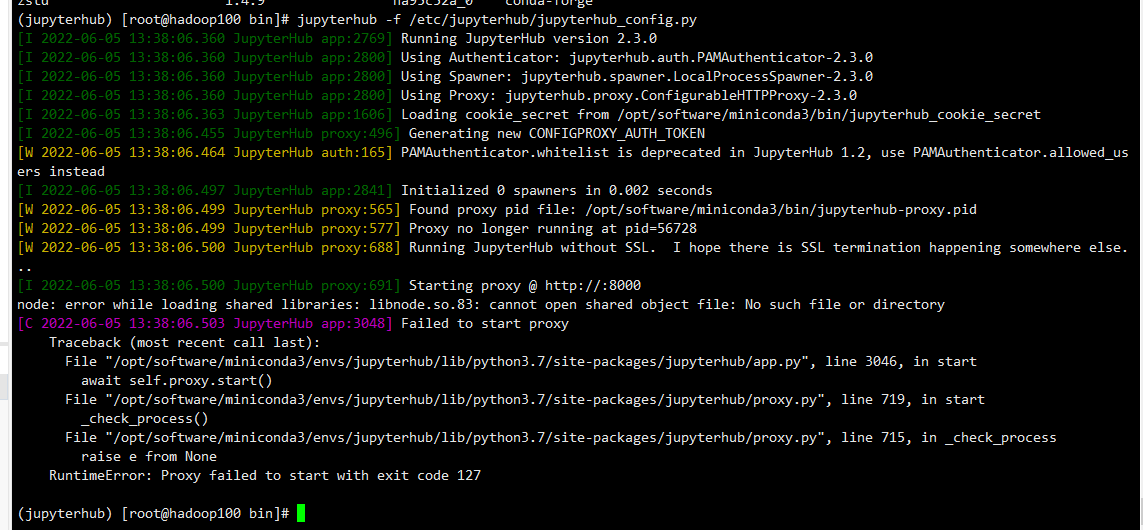
==解决思路:==
输入node -v可以看到同样的错误,可能是安装的node有问题,把之前通过pip安装的node卸载掉==(pip和conda 安装的都要卸载掉)==,通过tar包重新安装
重新安装建立软连接后是可以输入node -v,但是安装jupyterhub之后他会自带一个nodejs,还是会报错

猜测的原因是conda 安装的jupyterhub自带的nodejs可能有问题
通过pip的方式安装jupyterhub可以解决该问题
Linux 上安装 Node.js
|
|
==下面这个修改配置文件的方法不能生效==
解压文件的 bin 目录底下包含了 node、npm 等命令,我们可以修改linux系统的环境变量(profile)来设置直接运行命令:
老规矩先备份,养成修改重要文件之前先备份的好习惯。
|
|
然后 vim /etc/profile,在最下面添加 export PATH=$PATH: 后面跟上 node 下 bin 目录的路径
|
|
立即生效
|
|
OK!安装成功!
==建立软连接才能生效==
|
|
删除软连接:
进入软连接目录
rm ./node

==遇到的问题:==
直接通过web在插件模块install的话会出现如下错误,但是我启动jupyterhub的环境下已经安装了nodejs了,不知道为什么会出现该错误
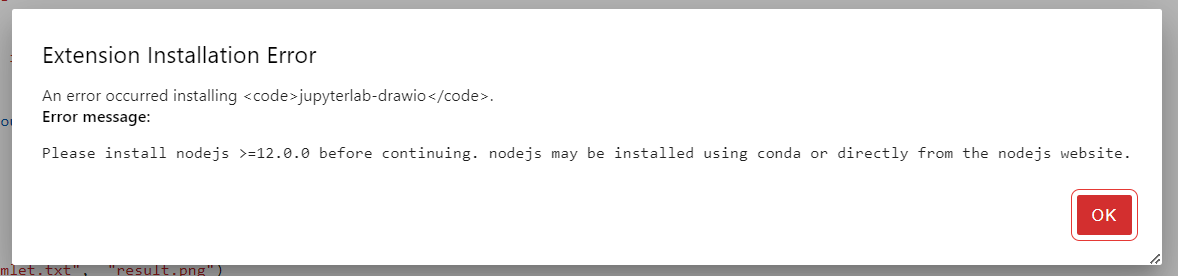
解决方法:
在linux中自己安装node,不要用自带的node环境
阿里天池的环境安装解决方案
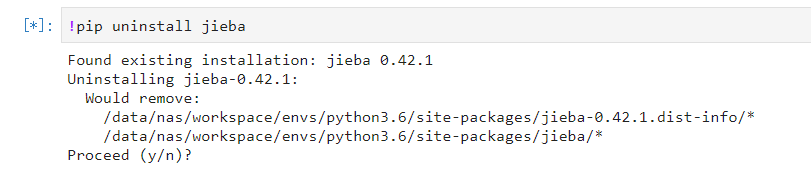
阿里天池可以通过 pip install 安装环境/插件(python环境安装在/data/nas/workspace/envs/python3.6/site-packages/)
阿里天池也没有办法通过插件模块install安装
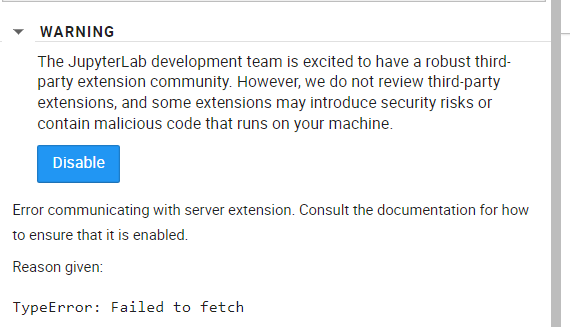
阿里天池也没有办法用命令!conda install -c conda-forge jieba -y安装环境
阿里天池也没有办法用命令!conda install -c conda-forge jupyterlab-drawio -y安装插件

Colab的环境安装解决方案
可通过pip install安装环境(python环境安装在/usr/local/lib/python3.7/dist-packages/),但是无法通过conda install,没有安装插件的模块
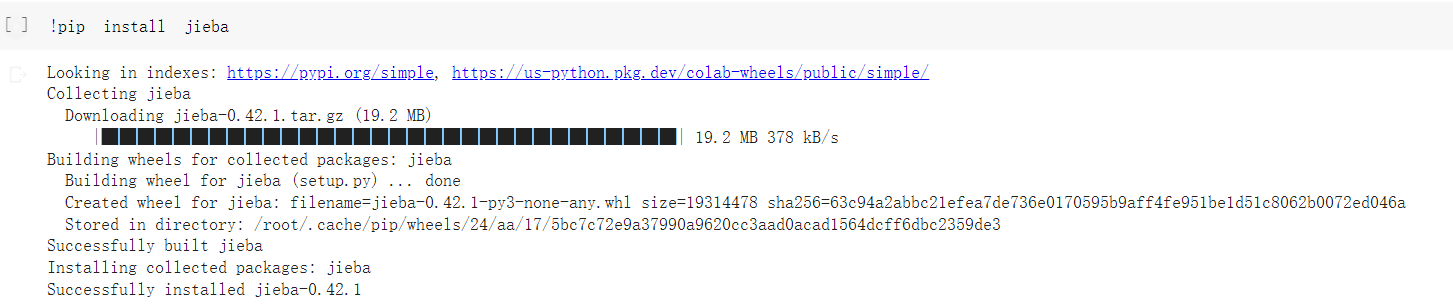
==Colab可以在输出端输入y执行之后的操作,但是阿里天池不可以==
Colab
阿里天池
The Littlest JupyterHub
The Littlest JupyterHub currently supports Ubuntu(18.04) Linux only
每个 JupyterHub 用户都会在首次启动服务器时创建自己的 Unix 用户帐户。这可以保护用户彼此之间,在/home为他们提供一个主目录,并允许基于文件系统权限进行共享。
安装TLJH
【TLJH】the-littlest-jupyterhub国内搭建和配置详细教程
conda 阿里源_Littlest JupyterHub| 01 Littlest JupyterHub 阿里云搭建
1.确保python3, python3-dev, curl 和 git 都已经安装
|
|
2.安装
下面这个安装不了,因为代码里面有GitHub的地址,下载很慢
|
|
==遇到的问题:==
启动报错
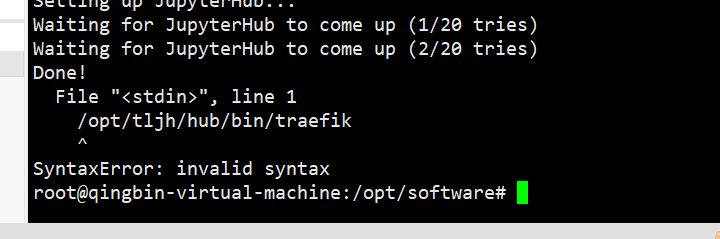
安装程序都做了些什么
TLJH创建的目录需要root权限/opt/tljh
Hub的环境安装在/opt/tljh/hub下,同时还包含了traefik(Træfik 是一个为了让部署微服务更加便捷而诞生的现代HTTP反向代理、负载均衡工具。 它支持多种后台 (Docker, Swarm, Kubernetes, Marathon, Mesos, Consul, Etcd, Zookeeper, BoltDB, Rest API, file…) 来自动化、动态的应用它的配置文件设置)
用户环境安装在 /opt/tljh/user,这包含用于启动所有用户的notebook接口,以及所有用户可用的各种包。这个环境归root用户所有。
不使用JupyterHub的原因
Jupytherhub的每个用户都是一个linux的用户,每个用户之间基于文件系统权限进行共享,用户的操作权限基本是遵循linux的规范,这不方便我们对用户的控制,开发环境、文件的管理与共享
Jupyter集成的应用
==集成的是Jupyter lab,通过Docker实现的,将一个外部目录挂载到容器中==
阿里天池大数据
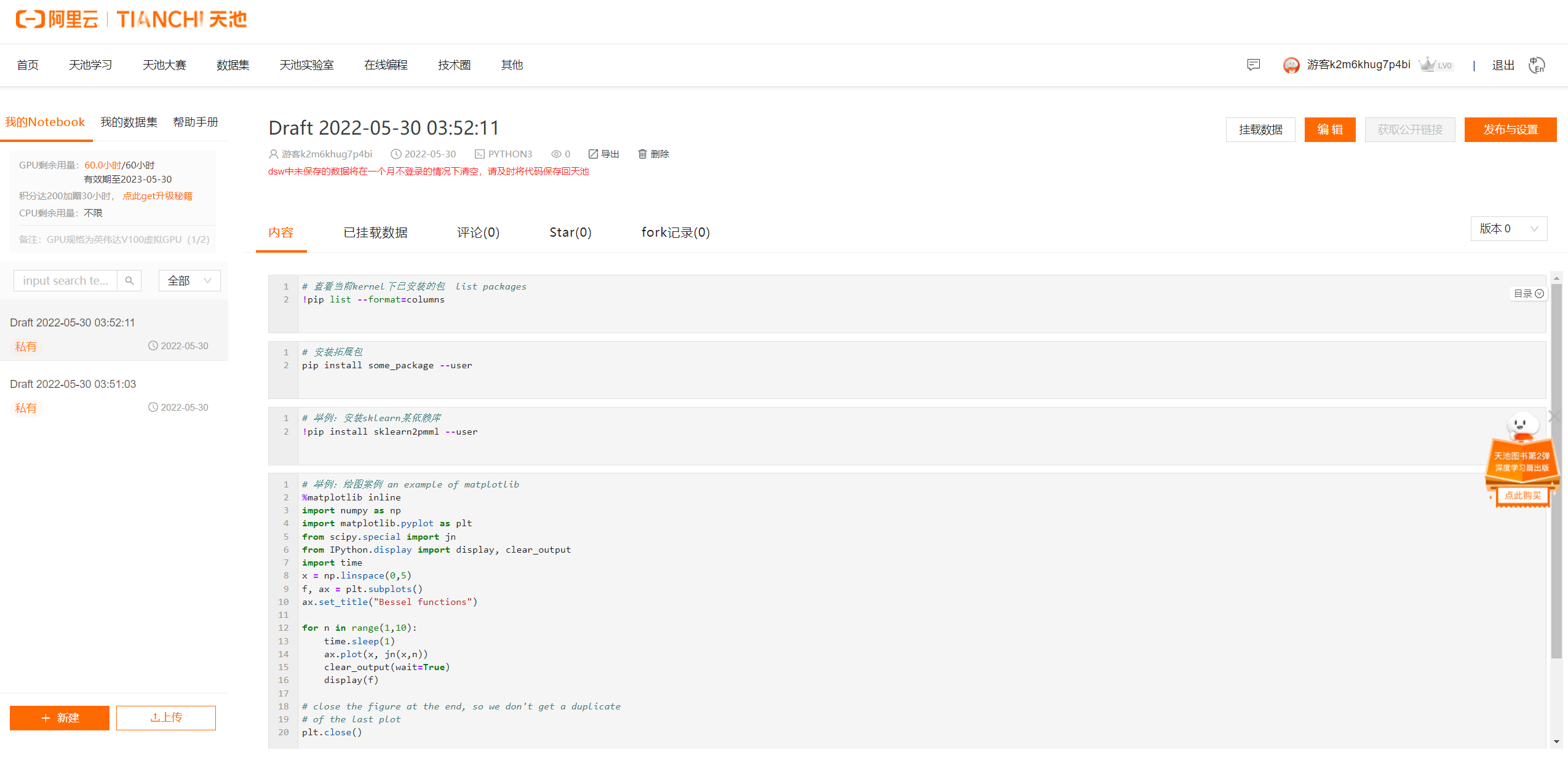
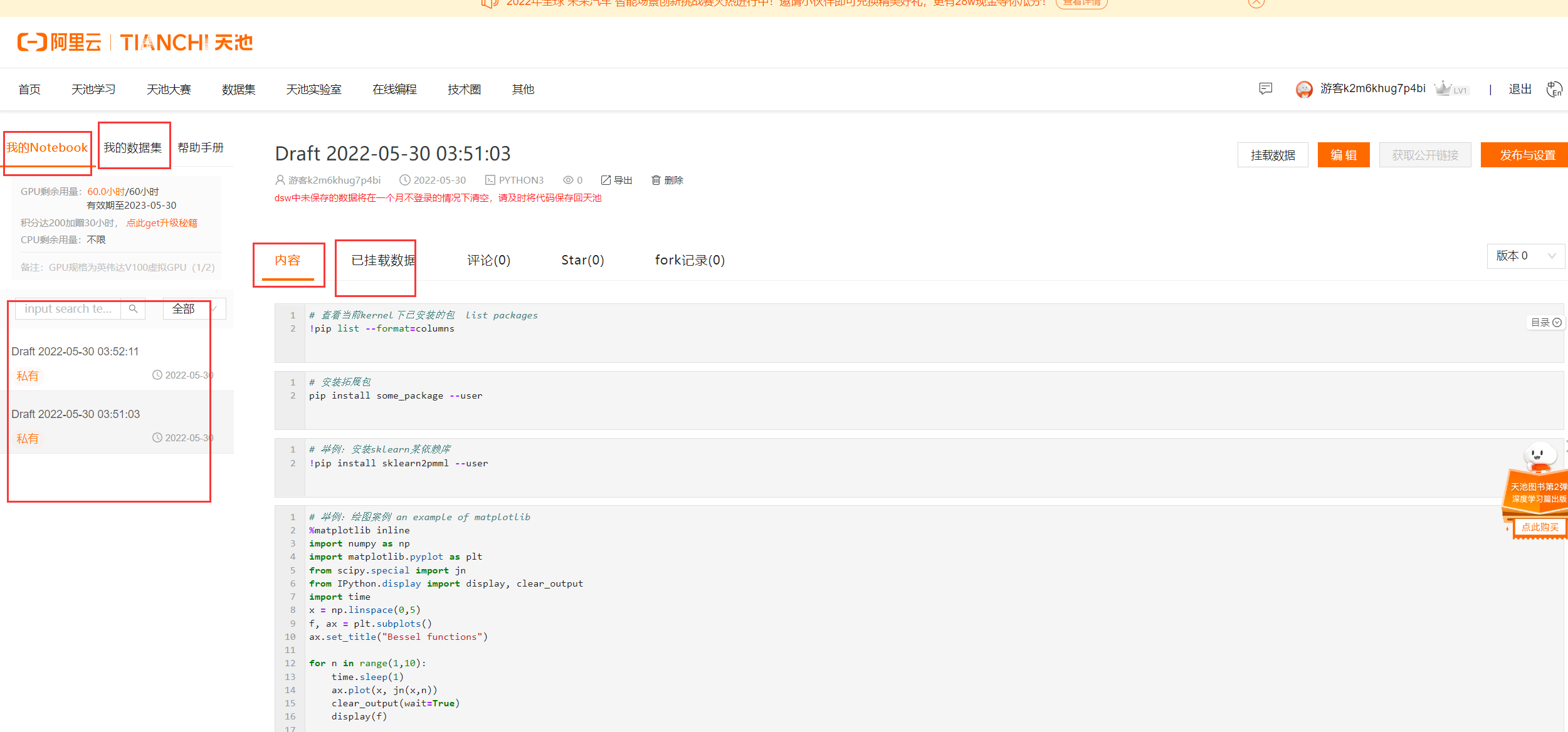
Google Colab
https://colab.research.google.com/
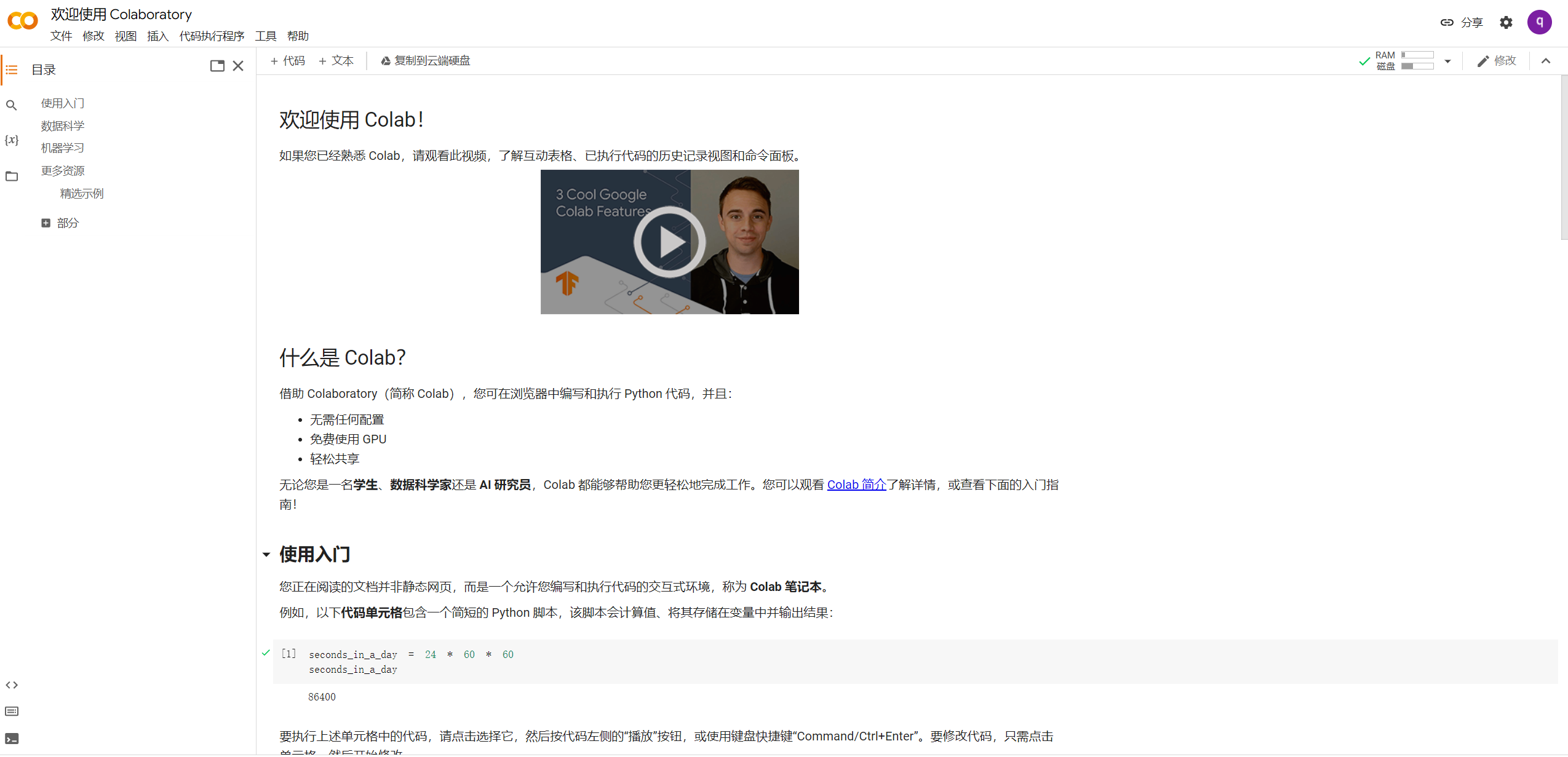

Jupyter二次开发
文件系统:glusterfs
用户权限:目前我们的Jupyter没有使用jupyterHub来管理用户权限,主要是我们的模式是==每个用户启动一个docker容器的jupyterLab服务==,每个人使用自己的jupyterLab服务,互相不会有干扰,而且JupyterLab我们定义为用户的IDE和工作平台,所以独立容器保证了独立性,也方便后续用户资源计费。在此架构下,==jupyterlab token作为用户认证主要途径,在jupyterLab系统启动时,会将用户的token存储到user service的用户表字段中==,前端页面跳转jupyterlab web UI时,会去user service获取该用户的jupyterLab token,根据此token登录jupyterLab服务,完成认证。 而==目录权限的控制,主要是不同的用户和机构目录挂载到不同的目录==。对于hadoop的访问权限控制,我们会把kerberos/ranger相关配置集成到了app中,并且jupyterLab服务和livy服务都会使用对应的用户USER ID来启动。
Jupyter Notebook二次开发的经验(一)——安装开发版本
JupyterHub+Lab:Ubuntu18.04搭建自己的多用户云notebook(安装篇)
Jupyter NoteBook / JupyterLab / JupyterHub 区别与关系简介
搭建环境方案(根据需求调整):
- 线上环境:The Littlest JupyterHub + JupyterLab
- 开发环境:JupyterHub + JupyterLab
不管是Jupyter Notebook还是Jupyter Lab,都是只支持单用户的使用场景,作为一个可交互的web服务,所有用户都在同一个目录下操作(甚至同时在编辑同一个脚本),多数情况下很不方便。Jupyterhub可以解决这个问题。 但是当我们把Jupyterhub安装,启动服务后默认确实JupyterNoteBook,如何换成JupyterLab呢?👇
JupyterLab on JupyterHub(JupyterLab+JupyterHub)(JupyterLab JupyterHub)
思路
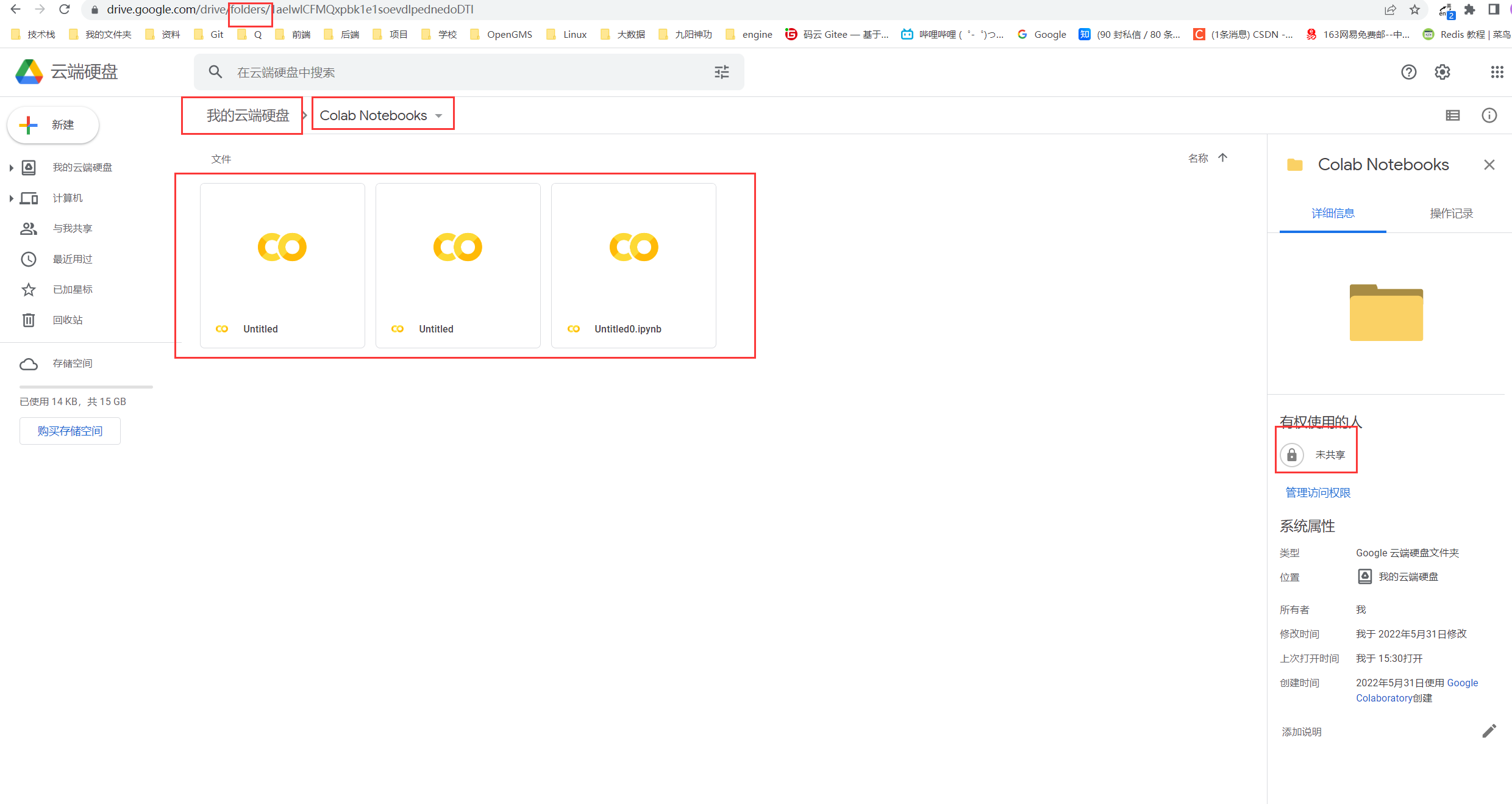
1.数据用Drive单独存储
2.写函数库让用户调用
例如:from google.colab import files
|
|
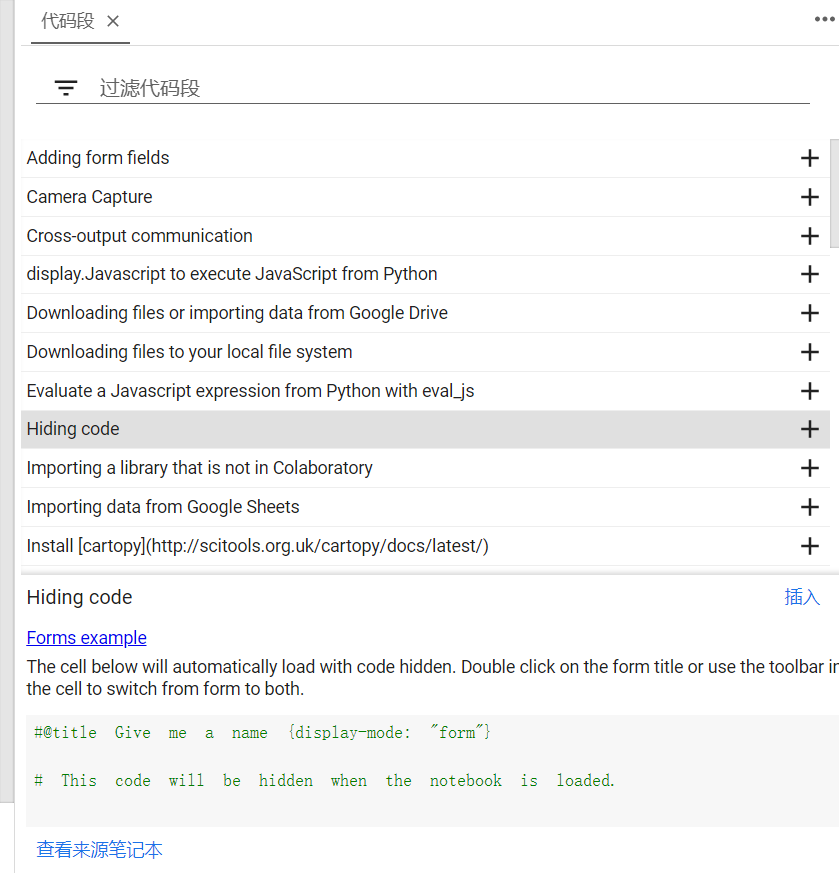
3.示例代码段
4.ipynb工程分享
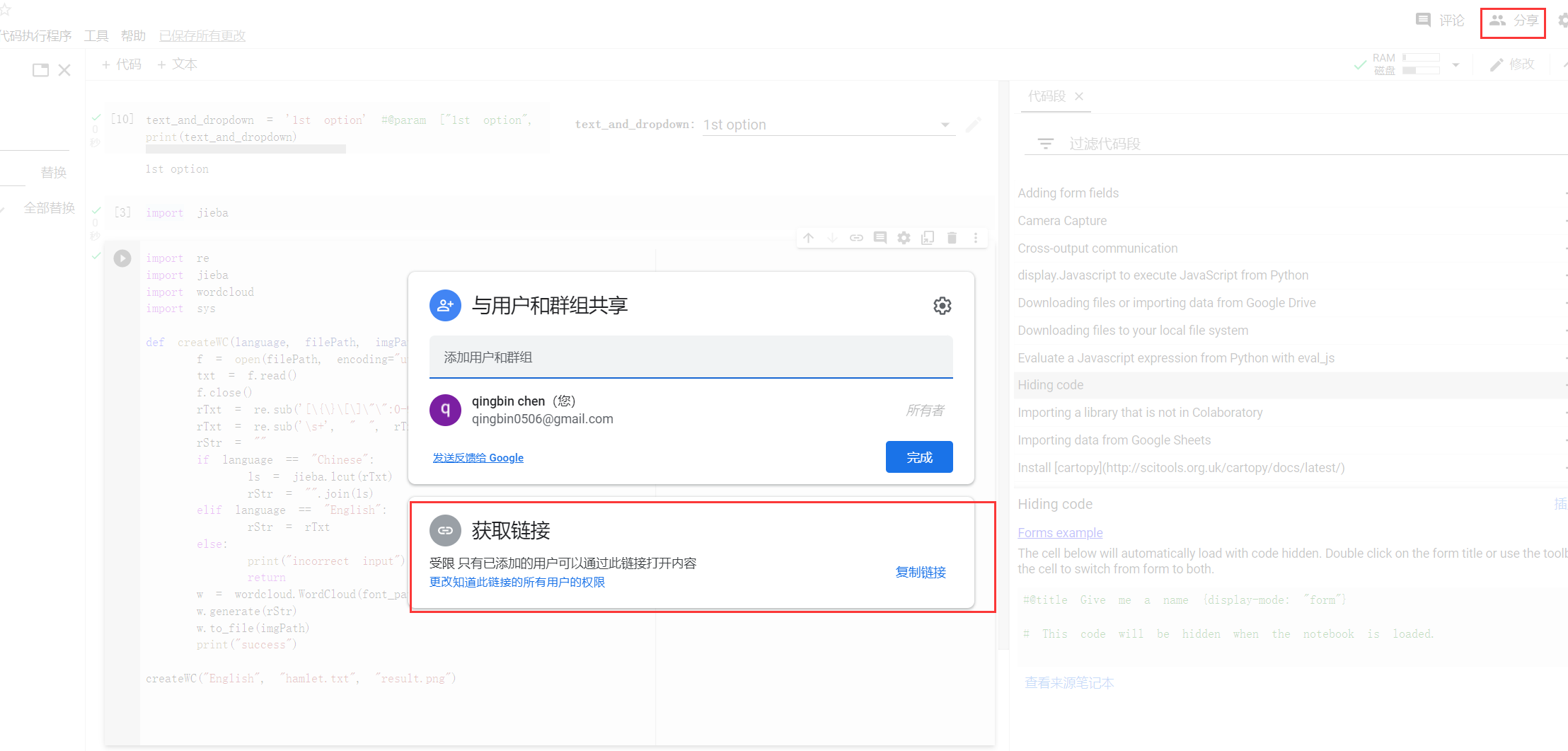
https://colab.research.google.com/drive/131SUrBstRNKv6n4GtK582ULCEjVaV1V9?usp=sharing
5.ipywidgets调参
6.服务的发布与共享
7.互操作引擎
问题收集
1.运行代码的时候出现错误,弹框提示内核似乎挂掉了,它很快将自动重启。
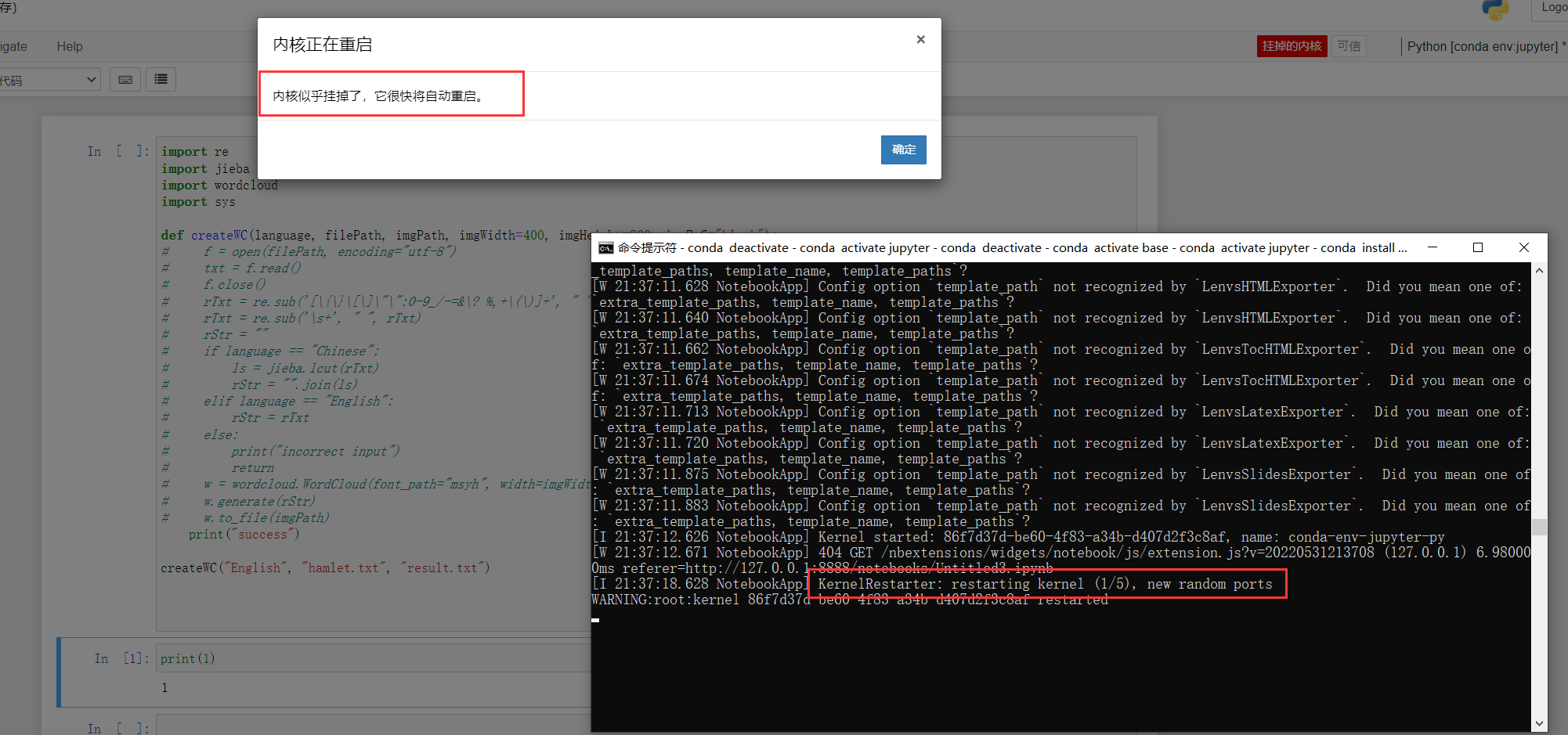
**解决:**出现这种情况的时候,需要将虚拟环境中的包全部用conda命令进行安装,用pip安装就会出现这个问题(把用pip安装的包删了重新用conda装:conda install -c conda-forge wordcloud)