1.GEE的产品形态和序列
1.1 GEE基本产品形态
已有的 GIS 云服务通常分为基础云服务(IaaS, Infrastructure as a Service)和 软件云服务(SaaS, Software as a Service)。
常见的基础云服务有 Google Cloud Platform、百度网盘等,具有较高的可定制性(High level of customizability),但其提供的功能通常局限于数据传输、共享等基础操作。
常见的软件云服务包括GLOBAL FOREST WATCH、Imazon、CLIMATE ENGINE 等,为特定的研究方向提供数据、技术和高度封装(High level of built-in functionality)的工具,功能丰富,但缺乏灵活性,难以支持多学科领域的交叉研究。
在此背景下,GEE 建立了一种平台级云服务(PaaS, Platform as a Service),在支持基础云服务的基础上,提供大量已封装的基础 GIS 方法与模型,供用户交互式或代码式调用,以支持复杂 GIS 分析与模拟的定制化操作。
GEE代码执行流程
程序运行时,Code Editor 会将编写的代码通过 API 接口发送给 GEE 后台;后台收到代码后,会根据代码逻辑==分配到不同服务器上操作==;显示的逻辑会经过后台计算后返回给编辑器地图界面显示,同时将输出的结果输出到数据报告栏中。通常情况下,运行结果以栅格的方式显示在地图显示区,还可对像素进行信息拾取,但对于一些属性或者统计类的报表信息,只能通过数据报告栏进行查询。同时,程序的运行调试也常常会利用数据报告栏对分步结果进行查看。==数据报告栏还可扩展为独立的 Task Manager 界面,支持任务结果的查询和筛选==。
1.2 GEE模块序列
GEE 是在 Google 数据中心系列支持技术上所建立的包括 Borg 集群管理系统、Spanner 分布式数据库、谷歌文件系统以及用于并行管道执行的 Flume Java 框架在内的云平台。
从 GEE 的应用角度考虑,GEE 的模块序列可以分为:
(1)底层的 Google 数据中心技术支撑,包括分布式数据存储技术、分布式计算技术、瓦片切图技术、并行计算和调度技术等
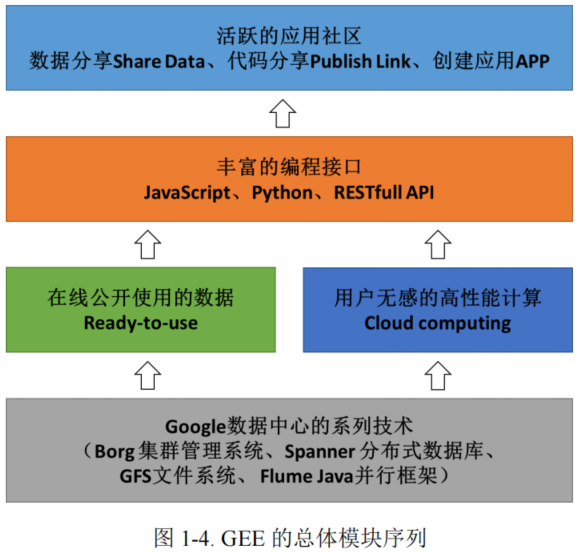
(2)中层的资源服务,包括在线公开使用的数据集和用户无感的高性能算。==在分布式高性能计算方面==,GEE 主要是使用了 Google 本身的分布式计算框架,按照 Java Just-In-Time (JIT)策略,将前端代码映射为 Java 程序,在 Flume Java 框架的支持下,实现了分布式的高性能计算。
(3)高层丰富的编程应用接口。GEE 本身提供了 Explorer 平台,供用户在网页上选择数据、选择计算方法,按照零编程的方式实现影像数据的分析。但此种方式较为局限,无法满足用户的定制式需求,尤其是在用户需要自定义分析算法的情况下。因此,GEE 提供了 Code Editor 平台。在此平台上,用户可以编写==脚本型代码(优化后的 Javascript)==,并且有丰富的示例代码来辅助用户进行开发。除了 Code Editor 这种在线工作模式,GEE 提供了 ==Python 接口==和 ==REST 风格调用接口==,辅助用户在编写 Python 脚本来调用远程的 GEE 服务、编程应用型的Javascript 代码来将 GEE 与 Web 应用相结合。
(4)与 Google 生态完美融合的应用社区。在以上底层-中层-高层模块框架
体系的基础上,GEE 与整个 Google 生态进行了整体性的融合。
1.3 GEE数据生态圈
(1)Earth Engine Data Catalog
GEE 提供了大量被广泛使用的地理空间数据集供用户在线调用。目前,地理空间数据集包含 700 多种数据,总数据量已经达到 50+ PB,且正以 1 PB/月的速度增长,基本接近实时更新。
(2)第三方数据 awesome-gee-community-datasets
一直以来,GEE 的用户都在积极地创建、上传和管理共享数据集。但绝大部分都不会被 GEE 纳入 Data Catalog 中。awesome-gee-community-datasets 填补了这一空白,支持用户将数据提交或推荐至该社区数据集,并在 GEE 中直接调用。
(3)个人 Cloud Assets
为支持跨学科复杂地理数据的计算与分析,GEE 积极鼓励用户上传个人数据,并提供了 250G 的默认资源空间(Legacy Assets),该空间中的数据仅与 GEE 账户相关联,不参与 GEE 的云端集成。每个用户仅有一个遗留资源空间。在Google Cloud Platform 的支持下,用户可进一步将数据上传至云端,获取更多的云资源空间(Cloud Assets)。
此外,基于一种身份与资源管理(Identity and Access Management , IAM)体系,用户可以通过定义谁(身份)对哪些资源具有哪种访问权限(角色)来精细化地管理访问权限。
1.4 GEE应用生态圈
==GEE 提供了 JavaScript、Python 和 REST 三种 API 接口,以多样化地支持用户调用服务,从而将复杂的地理空间分析转换为向 GEE 的请求。==
(1)基于 JavaScript 应用开发,主要是利用 Code Editor 平台,在线编写JavaScript 脚本代码(Google 稍加改进后的 JavaScript 语法),通过在线编程的方式调用 GEE 后台的数据服务和计算服务,获取数据分析的结果。
用户在 Code Editor 上创建的脚本文件都会拥有一个独立的标识符 ID,可以通过 Publish 的方式来共享链接,其他用户通过点击此链接可以直接访问脚本文集,并且该脚本执行的结果同样会直接共享给其他用户,这种方式又称为==快照Snapshot 模式==。
(2)基于 Python 应用开发,主要是面向离线型的用户。此处所谓的离线应用,并不是指脱离网络来开发,用户仍然需要联网并能够访问 GEE 的服务;只是编程的环境是离线的,主要是利用 Python 脚本来开发程序。在桌面端的 Python 编程环境中(例如 PyCharm、Spyder、Jupyter 等),可以==通过引入 GEE 的包的形式==,调用 GEE 的功能函数。==这些功能函数仍然会发送到 GEE 的后台服务,经过服务端的计算之后,能够获取相应的结果==。
GEE 本身也与 Google Cloud Service 联合,通过 ==Colaboratory(简称 colab)平台==能够在线进行 GEE 的 Python 编程。
(3)基于 REST API 应用开发,主要面向业务应用开发者,需要对网络服务相关知识具有一定的掌握。
基于 JavaScript的在线 Code Editor 能够帮助用户直接使用 GEE,门槛很低但局限在 Code Editor 平台本身;基于 Python 的 GEE 应用能够与整个 Python 的大生态相融合,形成 Python 语言环境的应用生态;而==基于 REST API 的 GEE 应用==,是在编程的底层构建了统一的访问协议,原则上能够与 C++、C#、Java、VB 等各种编程语言和环境相融合,融入到更加宽广的应用生态圈中。这种策略也是与 Google APP Engine 保持理念一致的。
在以上 JavaScript、Python、REST API 生态圈的基础上,GEE 还在横向上与一些常用的 GIS 分析工具开展了集成和融合,主要包括:
(1)GEE 与 QGIS 的集成。QGIS 本身开放有二次开发接口,并提供了 Python 语言的脚本开发环境(类似于 ArcPy)。GEE 与 QGIS 的集成同样是通过 Python 脚本的形式来完成。
(2)GEE与Jupyter的集成。==GEE 与 Jupyter 的集成构建了一个 geemap 平台==,通过配置 Jupyter 的环境,用户可以利用 Jupyter Notebook 来编写代码,无需依赖于 PyCharm、Spyder 等桌面端的编程 IDE。
(3)GEE 与 R 工具的集成。GEE 与 R 的集成并不是在底层语言上开展的,而是通过 R 语言来调用 GEE的 Python API。上层编码使用 R 语言,通过 rgee 在内部转换成 Python 的 API,再向 GEE 服务端请求,实现相关功能的调用。
(4)GEE 与 Julia 平台的集成。GEE 与 Julia 的集成同样是通过调用 GEE 的 Python API 来实现的,具体的技术流程与前述 R 类似。
2.GEE的技术演化路径及现行技术体系
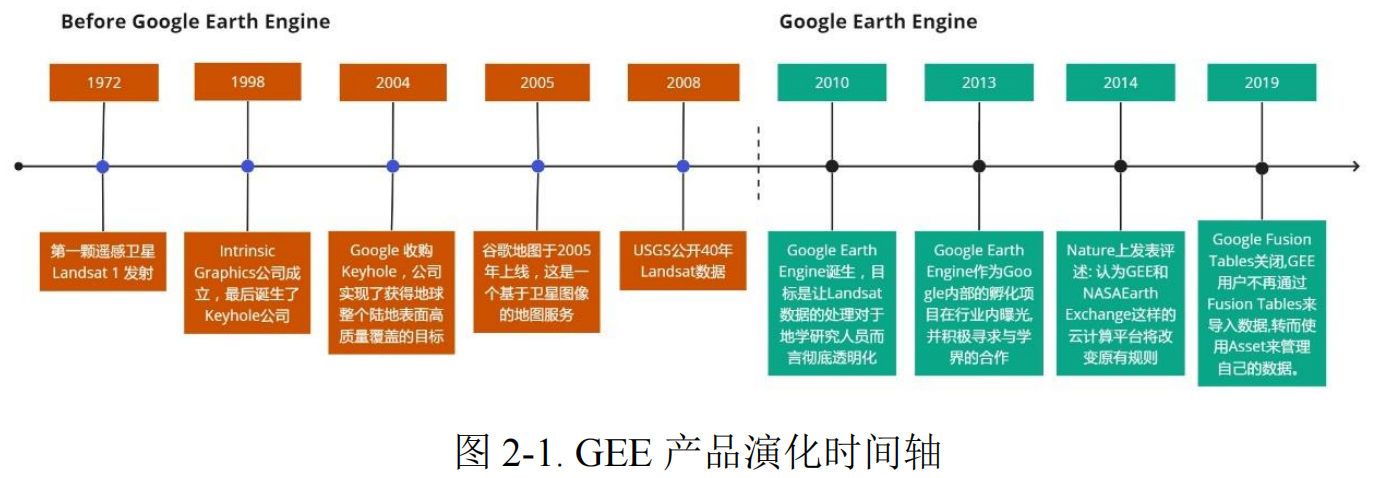
2.1技术演化路径
2.2现行技术体系
Google Earth Engine 从创建之初就是伴随着 Google 云服务总体布局而发展的,其在数据存储方面直接采用 Google 的分布式存储技术(如 ==BigTable== 等),在文件管理方面采用 Google 文件系统 ==GFS(Google File System)==,在分布式计算方面主要采用 ==Google MapReduce==,在集群管理方面采用 Google 的大规模集群管理系统(如 ==Borg== 等)。在此基础上,GEE 从以下四个层面开展了整体的架构设计:
(1)数据服务层,主要包括==瓦片化存储服务器==和==用户资源服务器==。瓦片化存储服务器主要是对 GEE 平台中大量的遥感影像数据、地理空间数据按照瓦片的方式进行切片、存储和管理。瓦片化的优势一方面体现在地图显示,按照分块的瓦片来请求数据能够降低网络请求的峰值压力,能够更好的与地图显示相结合;另一方面,==瓦片化后的数据也能够有效的支持并行计算==,尤其是在逐像素计算的相关分析应用,多个同时进行计算最后再合并可以大大提升计算效率。用户资源服务器主要是对 GEE 用户的个人数据进行管理。==通过 GEE 的 Assets 机制==,个人用户可以上传自己的数据,并且可以通过 URL 链接的方式分享自己的数据。
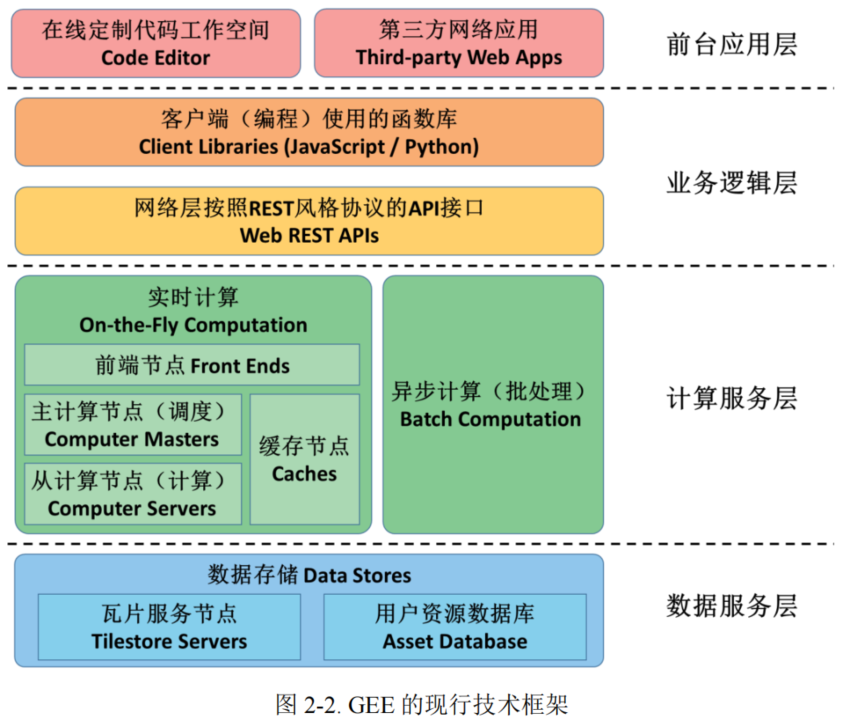
(2)计算服务层,主要包括==实时计算==和==异步计算==两种模式。实时计算是指用户通过编程接口来调用后台的算法服务,后台直接执行该算法并将结果返回到客户端。实时计算一般是用户地图展示和结果打印(GEE 的 print 函数),这种方式==在计算服务端通过利用 Google 的分布式集群管理、分布式并行计算等技术,极大提升了计算效率==,从而达到所谓“实时”的效果。本质上实时计算和异步计算在服务节点的调用方面并没有大的区别。异步计算主要是按照任务的方式来管理,用户创建任务后无需停留在页面等待,任务计算成功后按照配置的导出(GEE的 Export 函数)实现结果的保存。实时计算和异步计算在形式上的区别主要在于:==实时计算需要在页面等待,关掉页面后 print 的结果就丢失了;异步计算的任务可以在 Task Manager 任务管理器中查看,任务结束后直接保存结果==。
(3)业务逻辑层,主要是定义了 REST 风格的网络请求接口,并在 REST 网络接口的基础上定义了 JavaScript 和 Python 两种脚本语言的编程接口。GEE 的REST 接口遵循 GET、POST、UPDATE、DELETE 的协议风格,可以通过标准的网络请求协议来驱动后端服务(需通过身份验证)。由于网络编程对于遥感和 GIS 科研工作者而言并不普及,因而在此基础上 GEE 提供了更加易用易懂的脚本编程接口。最为常用的 JavaScript 脚本(Google 稍加了一些语法的改进),在 GEECode Editor 平台上的编程即通过此种脚本。JavaScript 脚本的方式主要是面向在线应用;此外还有针对离线应用的 Python 脚本。在 Python 脚本中同样定义了关于 GEE 的分析方法。
(4)前台应用层,主要包括了 Code Editor 平台、Explorer 平台和其他第三方网络应用。尤其是 Code Editor 平台,已经成为 GEE 的代表性应用平台。在Code Editor 平台上可以编写分析代码,并将分析应用结果发布成定制式的应用APP。用户可以将自己定制的 APP 发布成公开的网站,并加以推广。此外,一些研究机构和企业也可以基于 GEE 开发形成第三方网络应用。
2.3数据存储技术——分布式文件系统
分布式文件系统(Distributed file system, DFS)是一种允许文件通过网络在多台主机上分享的文件系统,它主要针对非结构化数据(文件),利用大量的计算机资源来同时完成大量的工作,以获取高性能和高可扩展性。
2.3.1 Google File System
Google File System(GFS、GoogleFS)是 Google 在 2003 年公布的分布式文件系统,它通过大量的普通廉价机器为海量的非结构化数据提供==高性能、高可用性和高扩展性==的分布式数据存储方案。无论在设计理念还是应用规模上,GFS 都是划时代的,但是现在看来 Google 当初的设计充满了简单粗暴。为了简化系统,GFS 仅适用于以下场景:
(1)文件系统中的文件大(GB 级及以上)而少
(2)对文件操作多为顺序读取、复写或追加,几乎没有随机访问
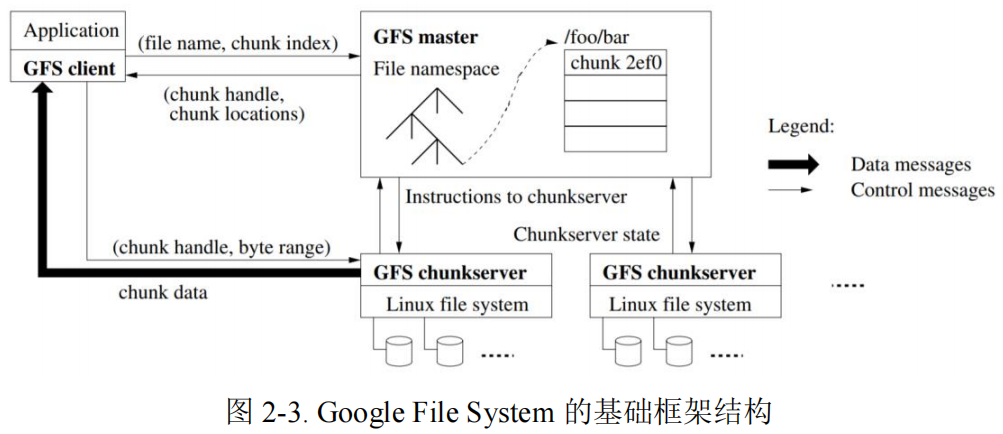
如图 2-2 所示,==一个 GFS 集群由一个管理节点(master)、多个块服务器(chunk server)和多个客户端(client)组成。==GFS 将元数据保存在 master 节点中,将客户端需要的数据分块(chunk)存储在多个 chunk server 中,client 首先访问 master节点,获取 chunk server 信息,再访问相关的 chunk server 完成数据的读写工作。这样的设计方法实现了控制流和数据流的分离,极大的减轻了 master 的负担,同时由于文件被分成多个块(chunk)进行分布式存储, client 可以同时访问多个chunk server,以支持 I/O 可以高度并行。
Chunk server 负责具体的数据存储工作,每个 chunk server 挂载多个磁盘设备并将其格式化为本地文件系统(如 XFS)。在 GFS 中,一个大的文件会被分为多个 chunks,chunk 是数据复制的基本单位,它的大小是固定的(默认是 64MB)。每个 chunk 拥有有全局唯一的文件句柄,它会被复制到多个 chunkserver(默认是3 个)以 Linux 的文件形式存储,以保证数据的可用性和可靠性。
Master 承担整个系统控制流枢纽的角色,它维护了所有元数据信息,包括文件命名空间、文件访问控制信息、块(chunk)位置信息和块到 chunkserver 的映射等信息;同时它也控制了整个系统的活动,包括租约(chunk lease)管理、孤儿块(chunk)垃圾回收和块在服务器之间的迁移;单 master 的设计支持系统能使用全局信息进行复杂的块放置和副本决策。然而由于只有一个 master 节点,系统必须尽可能减少 master 节点对读写的参与,优化节点之间的交互,避免 master处的负载过大。
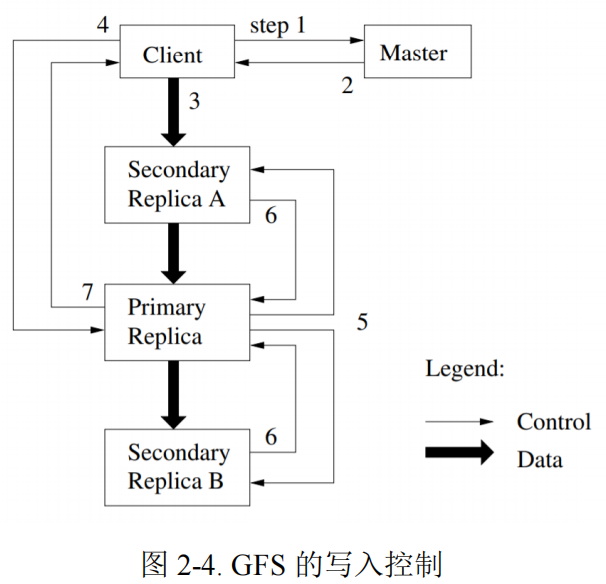
上图是 GFS 一次写的主要流程,步骤如下:
(1)client 向 master 询问 chunk 的首要副本和其他副本的位置等信息
(2)Master 返回首要副本的标识和所有副本的位置,client 缓存该数据
(3)Client 将数据发送到所有副本
(4)当所有副本确认收到数据,client 将发送写请求给首要副本
(5)首要副本转发写请求给所有副本
(6)所有副本回复首要副本操作结果
(7)首要副本回复 client,任何副本上的任何错误都会报告给客户端
2.3.2 HDFS
HDFS(Hadoop Distributed File System, Hadoop 分布式文件系统)是 Hadoop项目于 2004 年对 GFS 的开源实现。HDFS 虽然和 GFS 原理相同,但运算速度上达不到 Google 论文中的标准,并且在并发写的处理上,采用了一些简化的做法。尽管如此,==HDFS 算是开源分布式文件系统中最完整实现了 GFS 论文中的概念模型==。Hadoop 也由于其开源特性,使得它成为分布式计算系统事实上的国际标准。
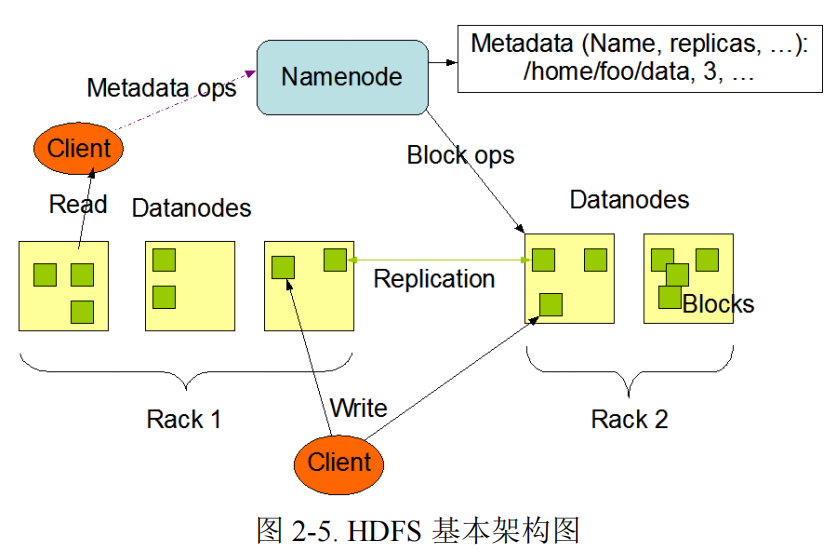
HDFS 集群由单个 NameNode,和多个 DataNode 构成。NameNode 管理文件系统命名空间的主服务器和管理客户端对文件的访问组成,如打开,关闭和重命名文件和目录。负责管理文件目录、文件和 block 的对应关系以及 block 和DataNode 的对应关系,维护目录树,接管用户的请求。DataNode(数据节点)管理连接到它们运行的节点的存储,负责处理来自文件系统客户端的读写请求,同时还执行块创建,删除。Client(客户端)代表用户通过与 NameNode 和 DataNode交互来访问整个文件系统,HDFS 对外开放文件命名空间并允许用户数据以文件形式存储。用户通过客户端(Client)与 HDFS 进行通讯交互。
GFS 与 HDFS 的共同点:
都采用单一主控机+多台工作机的模式,由一台主控机(Master)存储系统全部元数据,并实现数据的分布、复制、备份决策,主控机还实现了元数据的 checkpoint和操作日志记录及回放功能。工作机存储数据,并根据主控机的指令进行数据存储、数据迁移和数据计算等
都通过数据分块和复制(多副本,一般是 3)来提供更高的可靠性和更高的性能。当其中一个副本不可用时,系统都提供副本自动复制功能。同时,针对数据读多于写的特点,读服务被分配到多个副本所在机器,提供了系统的整体性能
都提供了一个树结构的文件系统,实现了类似与 Linux 下的文件复制、改名、移动、创建、删除操作以及简单的权限管理等
GFS 与 HDFS 的不同点:
GFS 支持多客户端并发 Append 模型,允许文件被多次或者多个客户端同时打开以追加数据;HDFS 文件只允许一次打开并追加数据,客户端先把所有数据写入本地的临时文件中,等到数据量达到一个块的大小(通常为 64MB),再一次性写入 HDFS 文件
GFS 采用主从模式备份 Master 的系统元数据,当主 Master 失效时,可以通过分布式选举备机接替,继续对外提供服务;而 HDFS 的 Master 的持久化数据只写入到本机,可能采用磁盘镜像作为预防,出现故障时需要人工介入
GFS 支持数据库快照,而 HDFS 不支持
GFS 写入数据时,是实时写入到物理块;而 HDFS 是积攒到一定量,才持久化到磁盘
2.3.3 Colossus
初代 GFS 应用场景十分有限,系统延迟很高,使用时不得不做出各种优化,并且一旦 master 出现问题将会导致严重的后果。因此 2013 年 Google 提出的第二代 GFS——Colossus,新系统拥有分布式元数据管理、1MB 的数据块和理论上无限大的目录规模支持。Colossus 的架构如下:
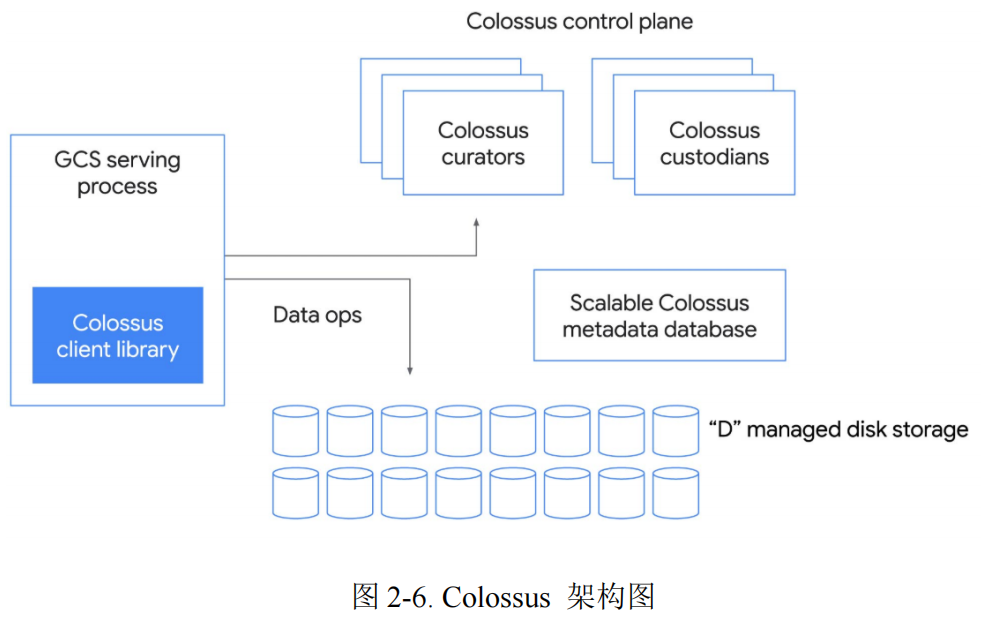
Scalable Colossus metadata database:分布式元数据管理子系统,但也是整个新系统的核心。==对应原系统的 Master Server==。
Client Library:应用程序或服务与 Colossus 交互的方式。
Colossus control plane:元数据服务,由许多的 curators 组成。
“D” managed disk storage: 数据块存储服务器,==对应原系统的 Chunk Server==。
2.4数据存储技术——分布式数据库
分布式文件系统适用于非结构化数据,且数据都以 key/value 的方式暴力存取。分布式数据库利用计算机网络将物理上分散的多个数据库单元连接起来组成的一个逻辑上统一的数据库。每个被连接起来的数据库单元称为站点或节点。分布式数据库有一个统一的数据库管理系统来进行管理,称为分布式数据库管理系统。
2.4.1 BigTable
BigTable 是 Google 于 2006 年公布的一个分布式结构化数据存储系统,它基于 GFS 构建,但是被设计用来处理海量数据:通常是分布在数千台普通服务器上的 PB 级的数据。
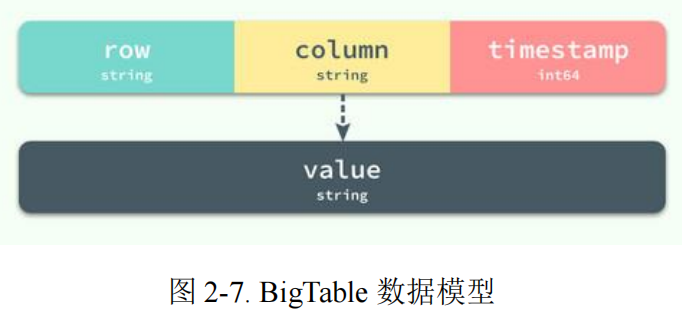
Bigtable 是一个稀疏的、分布式的、持久化存储的多维度排序 Map。即 BigTable 是一个持久化存储的包含海量 key-value 的 Map,这个 Map 按照 Key 进行排序,其中 Key 是一个由{Row Key, Column Key, Timestamp}组成的多维结构,每一行列的组成并不是严格的结构,最终 Map 通过多个分区来实现分布式。
Bigtable 是建立在其它的几个 Google 基础构件之上的。==BigTable 使用 Google 的分布式文件系统(GFS)存储日志文件和数据文件。==BigTable 集群通常运行在一个共享的机器池中,池中的机器还会运行其它的各种各样的分布式应用程序,BigTable 的进程通常要和其它应用的进程共享机器。BigTable 依赖集群管理系统来调度任务、管理共享机器上的资源,处理机器的故障以及监视机器的状态。==BigTable 内部存储数据的文件是 GoogleSSTable 格式的。SSTable 是一个持久化的、排序的、不可更改的 Map 结构。BigTable 还依赖一个高可用的、序列化的分布式锁服务组件,叫做 Chubby==。一个 Chubby 服务包括了 5 个活动的副本,其中的一个副本被选为 Master,并且处理请求。只有在大多数副本都是正常运行的,并且彼此之间能够互相通信的情况下,Chubby 服 务才是可用的。当有副本失效的时候,Chubby 使用 ==Paxos 算法==来保证副本的一致性。
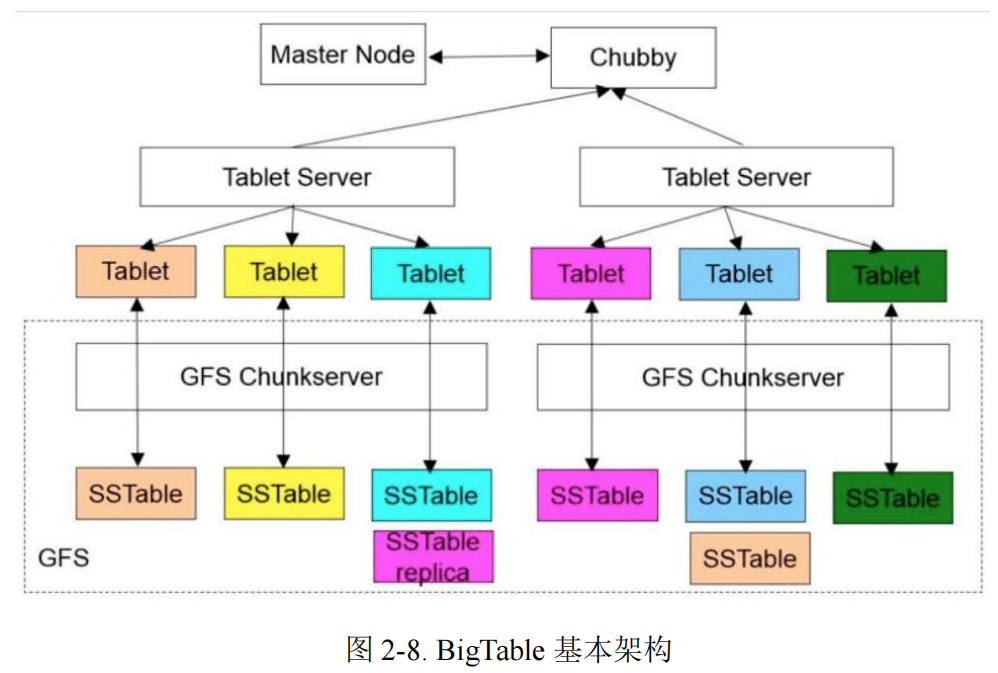
由上图可知,BigTable 包括了三部分:一个 Master Node、多个 Tablet Server 和 GFS 的支持。Master Node 主要负责以下工作:建立表、为 Tablet Server 分配 Tablets、检测新加入的或者过期失效的 Tablet 服务器、对 Tablet 服务器进行负载均衡、以及对保存在 GFS 上的文件进行垃圾收集。每个 Tablet Server 都管理一个 Tablet 的集合(通常每个服务器有大约数十个至上千个 Tablet)。每个 Tablet 服务器负责处理它所加载的 Tablet 的读写操作,以及在 Tablets 过大时,对其进行分割。一个 BigTable 集群存储了很多表,每个表包含了一个 Tablet 的集合,而每个 Tablet 包含了某个范围内的行的所有相关数据。初始状态 下,一个表只有一个 Tablet。随着表中数据的增长,它被自动分割成多个 Tablet,缺省情况下,每个 Tablet 的尺寸大约是 100MB 到 200MB。
2.4.2 HBase
HBase 是 Hadoop 项目于 2007 年对 BigTable 的开源实现,主要用来存储非结构化和半结构化的松散数据。HBase 非常接近 BigTable,采用了一样的数据模型,将协同服务管理从 ==Chubby 替换成了开源的 Zookeeper,将分布式文件存储系统 GFS 替换成了开源的 HDFS==。
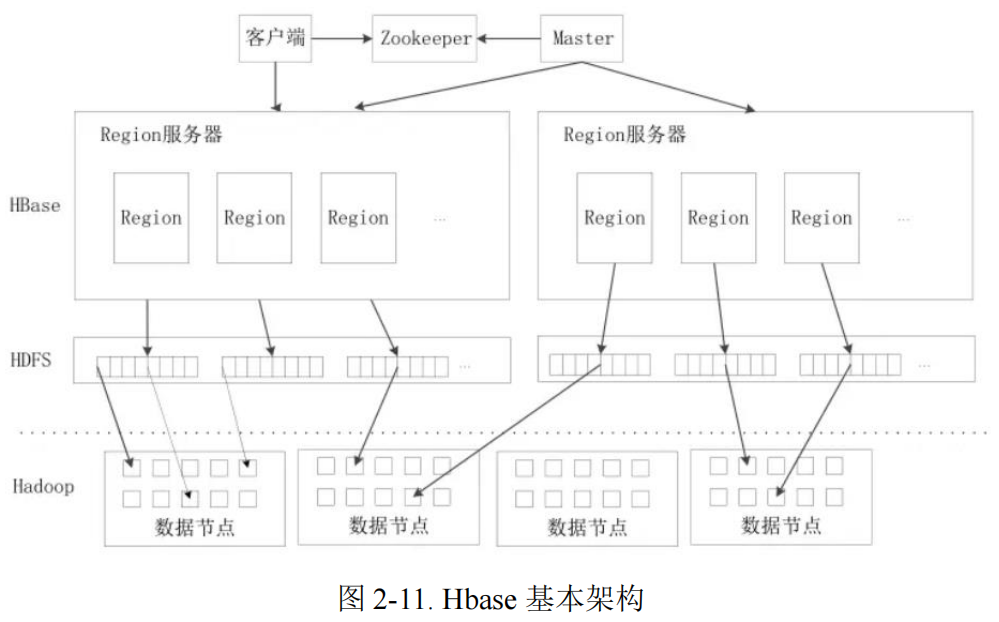
如上图所示,HBase 架构主要有:客户端、Zookeeper 服务器、Master 服务器、Region 服务器。客户端包含访问 HBase 的接口,同时在缓存中维护着已经访问过的 Region 位置信息,用来加快后续数据访问过程。==Zookeeper 是一个很好的集群管理工具,它可以帮助选举出一个 Master 作为集群的总管,并保证在任何时刻总有唯一一个 Master 在运行,这就避了 Master 的“单点失效”问题==。Master主要负责表和 Region 的管理工作,主要工作有:管理用户对表的增加、删除、修改、查询等操作、实现不同 Region 服务器之间的负载均衡、在 Region 分裂或合并后,负责重新调整 Region 的分布、对发生故障失效的 Region 服务器上的Region 进行迁移等。Region 服务器是 HBase 中最核心的模块,负责维护分配给自己的 Region,并响应用户的读写请求。
2.4.3 Spanner
Spanner 是 Google 于 2012 年公布的全球级分布式数据库,它==冲破了 CAP 原理的枷锁,在可扩展性、可用性、一致性三者之间达到了完美平衡==。Spanner 可以扩展到数百万台机器,数已百计的数据中心,上万亿的行,除了夸张的扩展性之外,它通过同步复制和多版本来满足一致性和可用性。BigTable 精简的数据模型支持用户动态的控制数据的分布和格式,但是对一些复杂的模型而言,很难维护其数据一致性。因此,Spanner 从一个类似 BigTable 的版本化键值存储(versioned key-value store)演进成了一个==多版本时态数据库(temporal multi-version database)==。数据被存储在模型化的半关系型表中;数据被版本化,且每个版本自动按照提交时间标记时间戳;旧版本遵循可配置的垃圾回收策略;应用程序可以读取时间戳较老的数据。Spanner 支持通用的事务,且提供了基于 SQL 的查询语言。
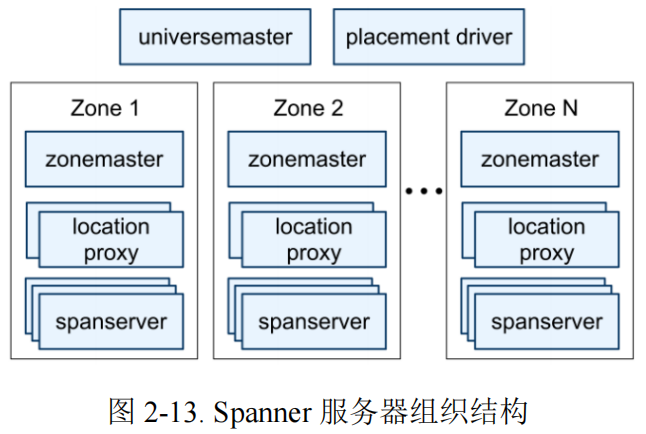
图 2-13 描述了 Sppanner universe 中的服务器。一个 zone 有一个 zonemaster和几百到几千个 spanserver。前者为 spannerserver 分配数据,后者向客户端提供数据服务。客户端使用每个 zone 的 location proxy 来定位给它分配的为其提供数据服务的 spanserver。universe master 和 placement driver 目前是单例。universe master 主要是一个控制台,其显示了所有 zone 的状态信息,以用来交互式调试。placement driver 分钟级地处理 zone 间的自动化迁移。placement driver 定期与 spanserver 交互来查找需要移动的数据,以满足更新后的副本约束或进行负载均衡。在最底层,每个 spanserver 负责 100 到 1000 个被称为 tablet 的数据结构实例。每个 tablet 都类似于 Bigtable 的 tablet 抽象,其实现了一系列如下的映射:(𝑘𝑒𝑦: 𝑠𝑡𝑟𝑖𝑛𝑔,𝑡𝑖𝑚𝑒𝑠𝑡𝑎𝑚𝑝: 𝑖𝑛𝑡64) → 𝑠𝑡𝑟𝑖𝑛𝑔 。
==Spannner 为数据分配时间戳,这是 Spanner 更像多版本数据库而不是键值存储的重要原因之一。==
2.5大数据分析及实时计算技术
2.5.1 MapReduce
MapReduce 是 Google 于 2004 年提出的一个处理和生成超大数据集的编程模型,它将海量数据处理的过程拆分为 ==map 和 reduce==。==用户首先创建一个 Map 函数处理一个基于 key/value pair 的数据集合,输出中间的基于 key/value pair 的数据集合;然后再创建一个 Reduce 函数用来合并所有的具有相同中间 key 值的中间 value 值。==基于 MapReduce 的程序能够在大量的普通配置的计算机上实现并行化处理。Map Reduce 在运行时只关心:如何分割输入数据、在大量计算机组成的 集群间的调度、集群中计算机的错误处理、管理集群中计算机之间必要的通信。没有并行计算和分布式处理系统开发经验的程序员可以通过 MapReduce 有效利用分布式系统的丰富资源。
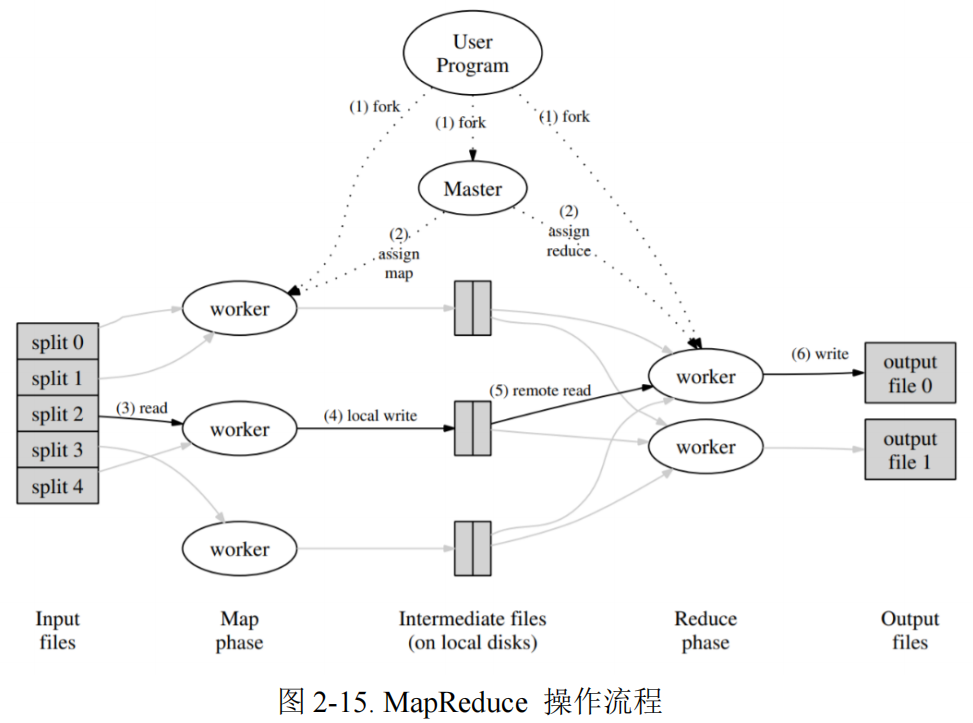
MapReduce 编程模型在 Google 内部成功应用于多个领域。MapReduce 的优势主要是:==封装了并行处 理、容错处理、数据本地化优化、负载均衡等等技术难点的细节、大量异构数据的解决、实现了一个在数千台计算机组成的大型集群上灵活部署运行的 MapReduce。==
2.5.2 Spark
Spark 是于 2010 年提出的基于内存计算的通用大规模数据处理框架。虽然MapReduce 提供了对数据访问和计算的抽象,但是==对于数据的复用就是简单的将中间数据写到一个稳定的文件系统中,会产生数据的复制备份,磁盘的 I/O 以及数据的序列化,所以在遇到需要在多个计算之间复用中间结果的操作时效率就会非常的低。==后来提出了一个新的模型 RDD,RDD 是一个可以容错且并行的数据结构(其实可以理解成分布式的集合,操作起来和操作本地集合一样简单),==它可以让用户显式的将中间结果数据集保存在内存中==,并且通过控制数据集的分区来达到数据存放处理最优化。Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。==让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的 API 提高了开发速度==。
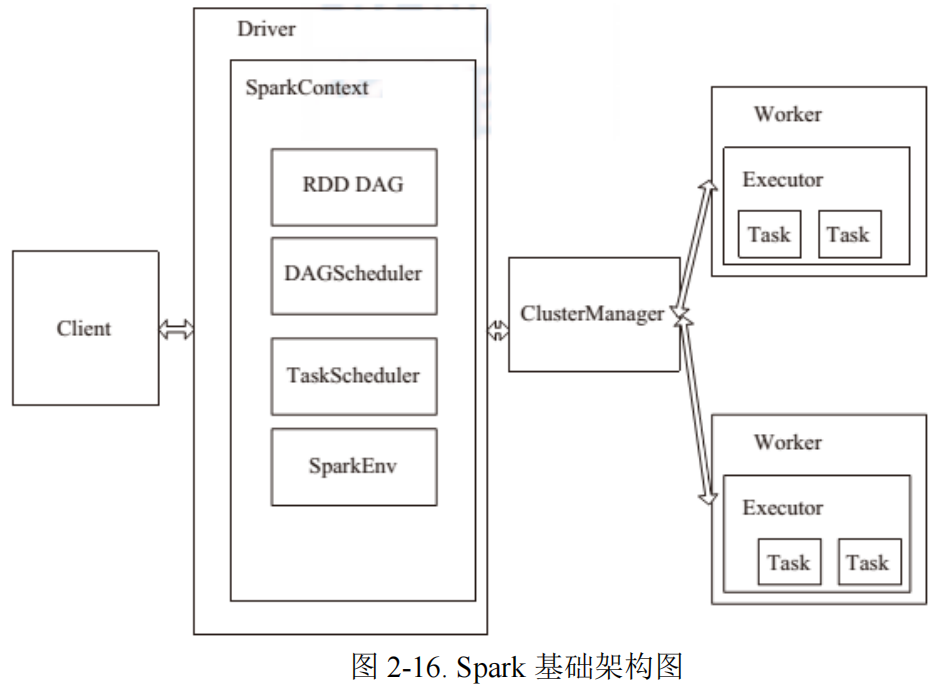
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD 具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD 允 许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
2.6 编排、管理、调度技术
大数据计算都是典型的分布式计算模型,是基于有向无环图(directed acyclic graph,DAG)或者大规模并行处理(massive parallel programming, MPP)迭代的计算模式,这意味着计算任务都是运行时才能生成的,因而难以进行预先调度,而分布式的特点又要求调度系统有更高的灵活性和自适应性。因此为了分布式存储能够高效稳定地运行数万个容器,就需要非常强大的服务编排系统。
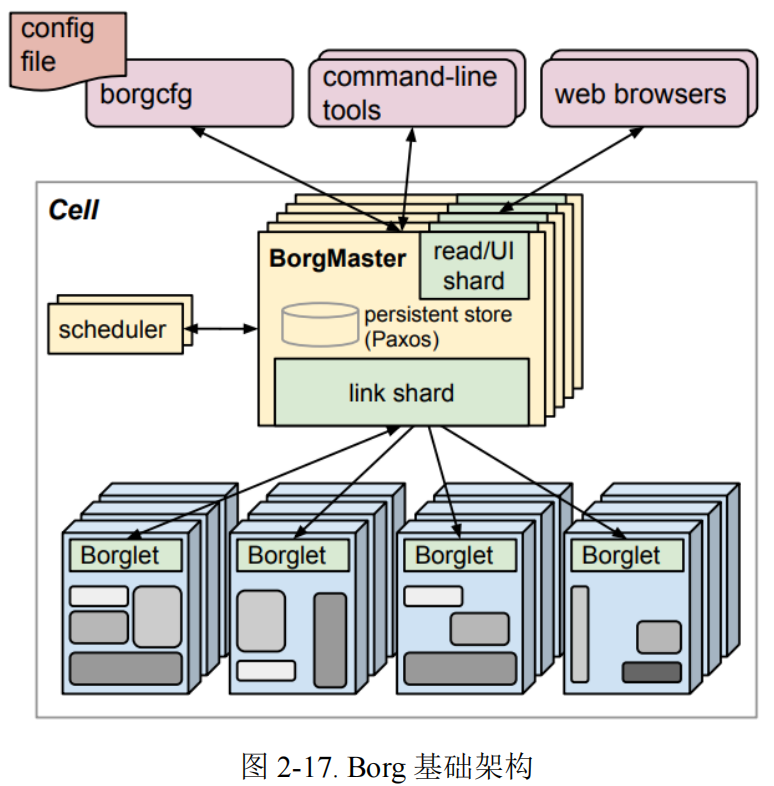
2.6.1 Borg
Borg 是 Google 于 2015 年提出的一个集群管理系统,上面运行着十万级的任务,数千个不同的应用,管理着数万台机器。==其通过权限管理、资源共享、性能隔离等来达到高资源利用率。==它能够支持高可用应用,并通过调度策略减少出现故障的概率,提供了任务描述语言、实时任务监控、分析工具等。Borg 主要三大优势:向用户隐藏资源管理和故障处理的细节,用户只需专注于应用程序开发;高可靠性和高可用性的操作,同时支持应用程序相关特性;有效的在数以万计的机器上运行工作负载。
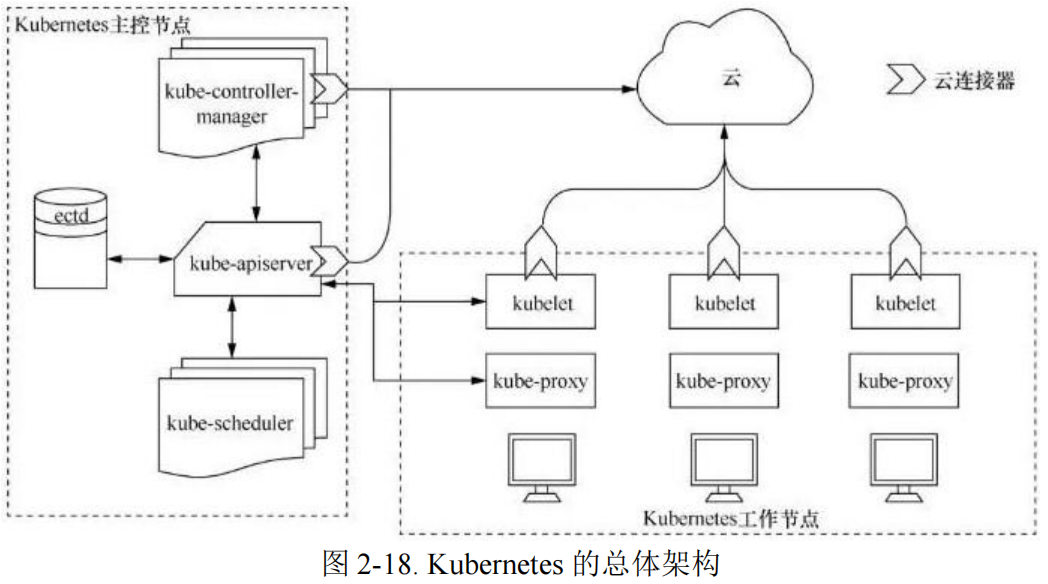
2.6.2 Kubernetes
Kubernetes 是 Google 开源用来管理 Docker 集群的项目,继承了 Borg 的优点,实现了编排、部署、运行以及管理容器应用的目的. Kubernetes 提供资源池化管理,可以将整个集群内的中央处理器(center processing unit,CPU)、图形处理器(graphic processing unit,GPU)、内存、网络和硬盘等资源抽象为一个资源池,可以根据应用的资源需求、资源池中的实时资源情况进行灵活调度;Kubernetes 包含一个统一的调度框架,最多可以管理数千个服务器和数万个容器,同时提供插件化的接口,让第三方来定制和扩展新的调度系统;此外 Kubernetes支持通过 ConfigMap 等方式动态地调整应用配置,从而具备动态调配的基础能力。
技术层分析
GEE 在技术总体上属于==封闭框架 Close Architecture==,底层严格依赖于 Google云服务,几乎没有办法与其他技术方案相融合。虽然 GEE 近期推出了商业化应用的方案,但仍然需要依托于 Google 云服务的基础框架。如果一个现有应用已经通过微软或者亚马逊的云服务框架开展了数据的云存储和管理,想利用 GEE来集成开展上层应用,目前是没有办法做到的。
GEE 在表面上属于轻应用、免费的平台,但其后台过于庞大(当然,也是其优势之所在)。在后台与前台之间,并没有明确的业务中台,因而也难以在 GEE平台上扩展新的应用。
相比而言,我们应当采用==开放架构 Open Architecture==,既支持普通用户的轻便使用,还要支持广大开发者的集成应用,需要与业务开发中广泛采用的技术框架(如Leaflet、Cesium 等前端框架,Hadoop、Spark 等后端框架,Kubernetes、Zookeeper等分布式框架)相集成,具有较高的解耦性和兼容性。