如果你的业务处于起步阶段,流量非常小,那无论是读请求还是写请求,直接操作数据库即可,这时你的架构模型是这样的:

但随着业务量的增长,你的项目请求量越来越大,这时如果每次都从数据库中读数据,那肯定会有性能问题。
这个阶段通常的做法是,引入「缓存」来提高读性能,架构模型就变成了这样:
当下优秀的缓存中间件,当属 Redis 莫属,它不仅性能非常高,还提供了很多友好的数据类型,可以很好地满足我们的业务需求。
但引入缓存之后,你就会面临一个问题:之前数据只存在数据库中,现在要放到缓存中读取,具体要怎么存呢?
Cache Aside Pattern(旁路缓存模式)#
Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删除 cache 。
缓存一致性问题#
并发引发的一致性问题#
2 个线程并发「读写」数据:
- 缓存中 X 不存在(数据库 X = 1)
- 线程 A 读取数据库,得到旧值(X = 1)
- 线程 B 更新数据库(X = 2)
- 线程 B 删除缓存
- 线程 A 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致。
这种情况「理论」来说是可能发生的,其实概率「很低」,这是因为它必须满足 3 个条件:
- 缓存刚好已失效
- 读请求 + 写请求并发
- 更新数据库 + 删除缓存的时间(步骤 3-4),要比读数据库 + 写缓存时间短(步骤 2 和 5)
为了避免这种情况的发生,采取写数据库时「加锁」的方式,防止其它线程对缓存读取和更改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
public int update(String sql, Object... params) {
SqlPair key = new SqlPair(sql, params);
// 加写锁, 防止其它线程对缓存读取和更改
lock.writeLock().lock();
try {
int rows = genericDao.update(sql, params);
map.clear();
return rows;
} finally {
lock.writeLock().unlock();
}
}
public T queryOne(Class<T> beanClass, String sql, Object... params) {
SqlPair key = new SqlPair(sql, params);
// 加读锁, 防止其它线程对缓存更改
lock.readLock().lock();
try {
T value = map.get(key);
if (value != null) {
return value;
}
} finally {
lock.readLock().unlock();
}
// 加写锁, 防止其它线程对缓存读取和更改
lock.writeLock().lock();
try {
// get 方法上面部分是可能多个线程进来的, 可能已经向缓存填充了数据
// 为防止重复查询数据库, 再次验证
T value = map.get(key);
if (value == null) {
// 如果没有, 查询数据库
value = genericDao.queryOne(beanClass, sql, params);
map.put(key, value);
}
return value;
} finally {
lock.writeLock().unlock();
}
}
|
通过上述加锁的逻辑,采取「先更新数据库 + 再删除缓存」的方案,是可以保证数据一致性的
删除缓存失败引发的一致性问题#
「先更新数据库 + 再删除缓存」中第二步执行「失败」导致数据不一致的问题
如何保证两步都执行成功?
答案是:重试。
最佳实线是采取异步重试的方案
把重试请求写到「消息队列」中,然后由专门的消费者来重试,直到成功。
或者更直接的做法,为了避免第二步执行失败,我们可以把操作缓存这一步,直接放到消息队列中,由消费者来操作缓存。
删除缓存操作投递到消息队列中#
所以,引入消息队列来解决这个问题,是比较合适的。这时架构模型就变成了这样:
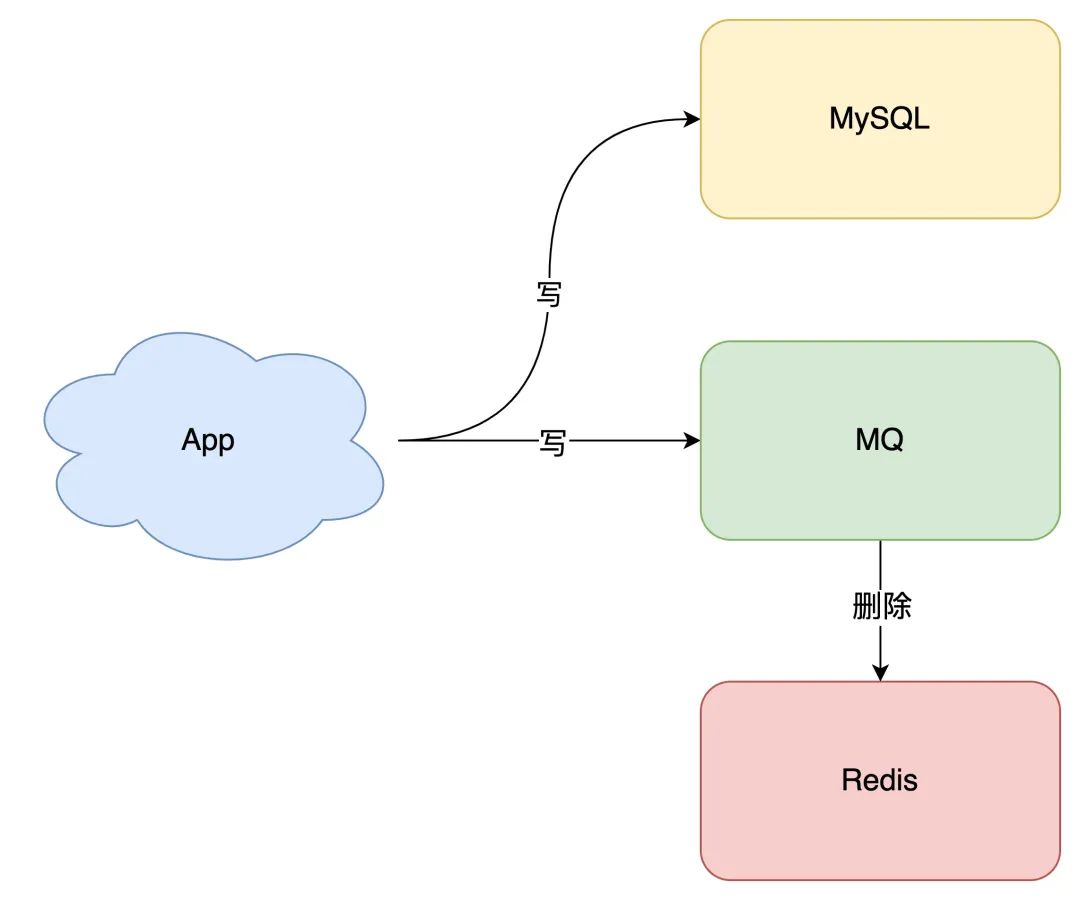
代码实现
采取的是RabbitMQ作为消息队列
更新业务
清除缓存操作交给rabbitmq listener处理
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public int update(String sql, Object... params) {
SqlPair key = new SqlPair(sql, params);
// 加写锁, 防止其它线程对缓存读取和更改
lock.writeLock().lock();
try {
int rows = genericDao.update(sql, params);
// map.clear();
MqUtils.sendRedisKeyToMq(key); // 清除缓存操作交给rabbitmq listener处理
return rows;
} finally {
lock.writeLock().unlock();
}
}
|
MqUtils
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public class MqUtils {
/**
* redis键
* @param redisKey redis键
* @author 7bin
**/
public static void sendRedisKeyToMq(String redisKey){
// 1.准备消息
Message message = MessageBuilder
.withBody(redisKey.getBytes(StandardCharsets.UTF_8))
.setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT)
.build();
// 2.发送消息
RabbitTemplate rabbitTemplate = SpringUtils.getBean("rabbitTemplate");
rabbitTemplate.convertAndSend("redis.queue", message);
}
}
|
RabbitMqListener
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@Slf4j
@Component
public class RabbitMqListener {
@Autowired
private RedisCache redisCache;
@RabbitListener(queues = "redis.queue")
public void listenRedisQueue(String msg) {
log.info("清除缓存: [ key: {} ]", msg);
redisCache.del(msg);
}
}
|
yml配置
开启重试机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
spring:
rabbitmq:
host: 172.21.212.177 # rabbitMQ的ip地址
port: 5672 # 端口
username: binbin
password: binbin
virtual-host: / # 虚拟主机
listener:
simple:
prefetch: 1 # 每次从MQ中取出一条消息进行消费
acknowledge-mode: auto # 自动确认
retry:
enabled: true # 开启重试机制
initial-interval: 1000 # 重试间隔时间
multiplier: 3 # 重试倍数
max-attempts: 4 # 最大重试次数
|
数据库更新日志投递到消息队列中#
那如果你确实不想在应用中去写消息队列,是否有更简单的方案,同时又可以保证一致性呢?
方案还是有的,这就是近几年比较流行的解决方案:订阅数据库变更日志,再操作缓存。
具体来讲就是,我们的业务应用在修改数据时,==「只需」修改数据库,无需操作缓存==。
那什么时候操作缓存呢?这就和数据库的「变更日志」有关了。
拿 MySQL 举例,当一条数据发生修改时,MySQL 就会产生一条变更日志(Binlog),我们可以订阅这个日志,拿到具体操作的数据,然后再根据这条数据,去删除对应的缓存。
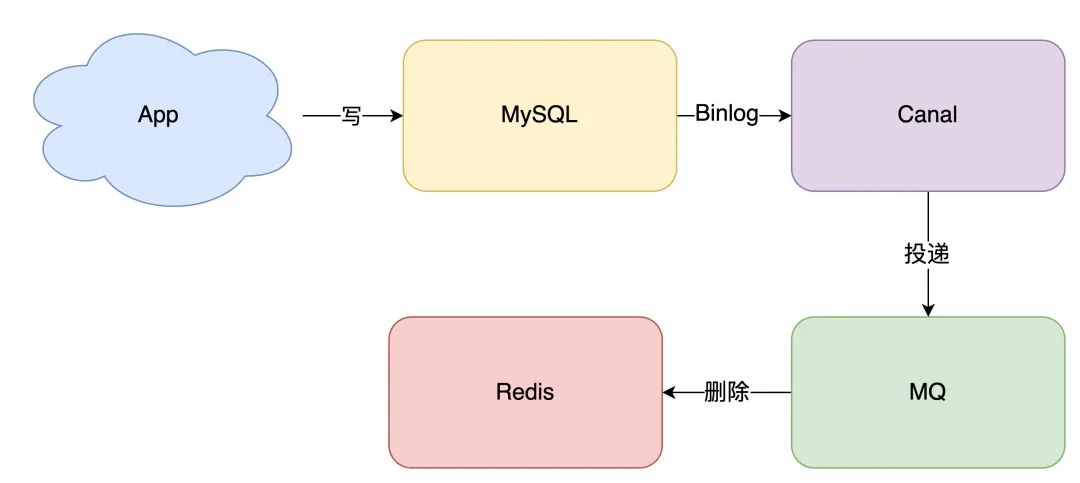
订阅变更日志,目前也有了比较成熟的开源中间件,例如阿里的 canal,使用这种方案的优点在于:
- 无需考虑写消息队列失败情况:只要写 MySQL 成功,Binlog 肯定会有
- 自动投递到下游队列:canal 自动把数据库变更日志「投递」给下游的消息队列
canal代码示例
代码实现
rabbitmq+canal
首先配置Mysql整合rabbit
参考链接:https://blog.csdn.net/qq_37487520/article/details/126078570
mq队列监听代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
@Slf4j
@Component
public class RabbitMqListener {
@Autowired
private RedisCache redisCache;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "canal.queue"),
exchange = @Exchange(name = "canal.fanout", type = ExchangeTypes.FANOUT),
key = {"canal"}
))
public void listenCanalQueue(Message mqMessage, Channel channel) {
String message = new String(mqMessage.getBody(), StandardCharsets.UTF_8);
// 解析message转换成CanalMessage对象
CanalMessage canalMessage = JSONUtil.toBean(message, CanalMessage.class);
String type = canalMessage.getType();
if (type == null) {
log.info ("unknown type {}", canalMessage.getType());
return;
}
if (type.equals("INSERT") || type.equals("UPDATE") || type.equals("DELETE")) {
handleRedisCache(canalMessage.getTable(), canalMessage.getData());
} else {
log.info("ignore type {}", canalMessage.getType());
}
}
private void handleRedisCache(String tableName, Object data) {
// 根据表名和字段名获取缓存key
String key = getKey(tableName, data);
redisCache.del(key);
log.info("清除缓存: [ key: {} ]", key);
}
String getKey(String tableName, Object data) {
// 构建redis key的逻辑
}
}
|
下面是不走消息队列,直接通过cannal监听MySQL的变化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
|
@Slf4j
@Component
public class MysqlDataListening {
private static final ThreadFactory springThreadFactory = new CustomizableThreadFactory("canal-pool-");
private static final ExecutorService executors = Executors.newFixedThreadPool(1, springThreadFactory);
@Autowired
RedisCache redisCache;
@PostConstruct
private void startListening() {
executors.submit(() -> {
connector();
});
}
void connector(){
log.info("start listening mysql data change...");
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120;
// while (emptyCount < totalEmptyCount) {
while (true) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
// emptyCount++;
// System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
// emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
// System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE || eventType == EventType.UPDATE || eventType == EventType.INSERT) {
// 增删改操作删除redis缓存
// printColumn(rowData.getAfterColumnsList());
handleRedisCache(entry.getHeader().getTableName(), rowData.getAfterColumnsList());
} else {
// 其他操作
// System.out.println("-------> before");
// printColumn(rowData.getBeforeColumnsList());
// System.out.println("-------> after");
// printColumn(rowData.getAfterColumnsList());
}
}
}
}
private void printColumn(List<Column> columns) {
for (Column column : columns) {
log.info(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
private void handleRedisCache(String tableName, List<CanalEntry.Column> columns) {
// 根据表名和字段名获取缓存key
String key = getKey(tableName, columns);
redisCache.del(key);
}
}
|
实现参考
mysql与缓存数据不一致解决-canal+mq方案
通过上述的解决方案基本可以实现缓存与数据库的一致性
参考链接
缓存和数据库一致性问题,看这篇就够了