引言
设计工作流的目的:
实现模型的自动化执行:对于一个需要繁琐步骤,通过多种方法计算的需求来说,通过构建工作流,可以省去一些重复的工作
实现模型的并行化计算:对于一整个计算流程来说,有些计算是可以一起执行的,因此可以根据计算的先后顺序构建出一整个计算流程,缩短一整个计算流程的运行时间
工作流是一种为满足数据收集、处理、计算、分析需求,按照流程之间的逻辑关系进行描述并使用计算机完成自动或半自动流程运行的过程。
工作流模型
工作流的执行传递依赖于流程中的数据流,单元与单元之间的依赖关系实际上是一种输入输出数据之间的有向传递关系
构建工作流时,各计算单元是按一定逻辑组织的,流程中包含顺序、选择、迭代等逻辑结构,各个元素的执行顺序也有先后,需要对流程的运转进行控制。
在对流程完成定义和构建之后,工作流需要对工作流流程进行分析,对流程中过程进行验证。根据其中的逻辑关系对执行先后顺序进行控制;并针对各功能单元进行解析,对包含计算任务的单元进行调度与运行。
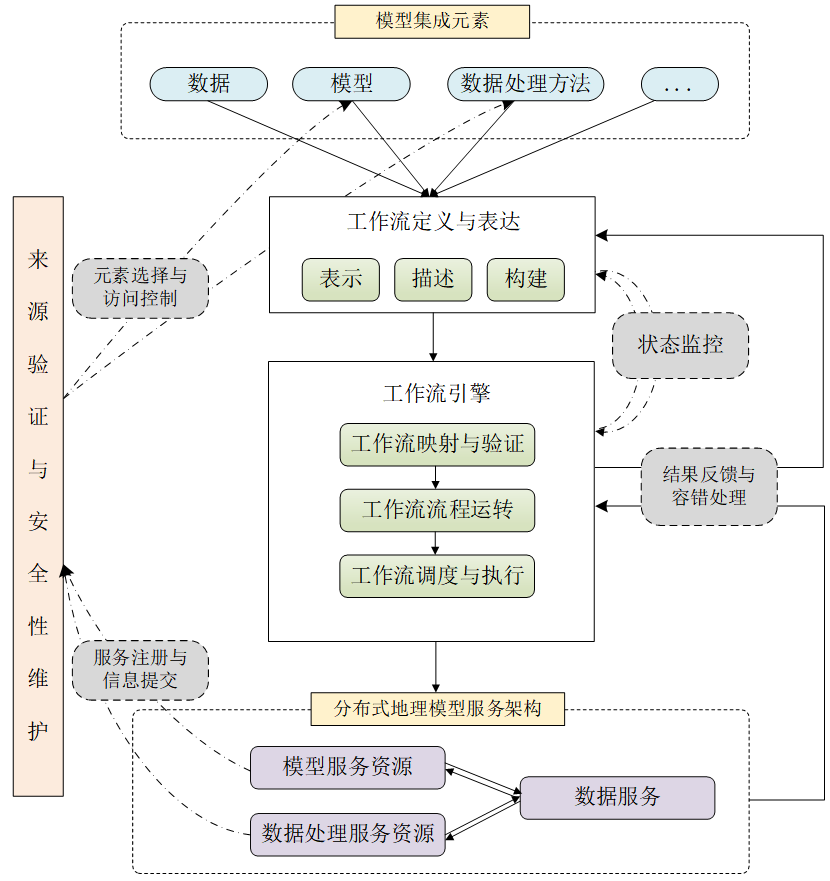
各计算节点的元素关系
1)串行关系
2)并行关系
3)分支关系
4)选择关系
5)迭代关系
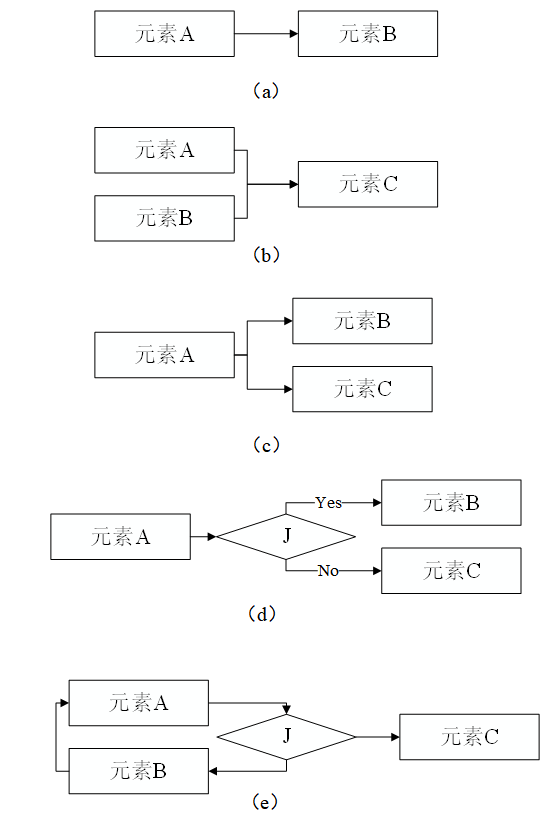
结构化描述文档
结构化描述模块示意图
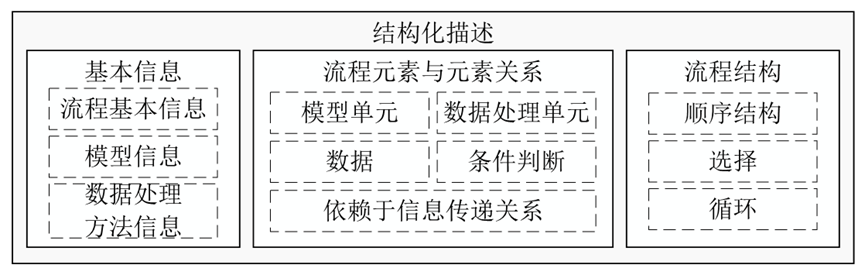
结构化描述文档

工作流对象类图
浏览器的Event Loop
参考链接:
JS是单线程还是多线程的?
答案:JS是单线程。如果您深究为什么是单线程的呢?
其实这是与它的用途有关,因为JS是一门浏览器脚本语言,主要用途是进行用户操作和操作DOM,所以它只能是单线程的,否则会带来很多复杂的同步问题。
浏览器是多进程还是单进程
答案:浏览器是多进程的。为什么说是多进程的? 你说是就是吗? 凭什么呢?
当我们浏览网页的时候,有的时候是不是会遇到浏览器卡死的情况。如果我们开了多个会话,就假如我们一边刷力扣,一边开发程序,写循环的时候,写了一个死循环,导致了我们开发的这个会话的崩溃,如果浏览器是单进程的情况下,力扣这个时候也会崩溃。
当然浏览器肯定不会允许这样的事情发生,它就是多进程的,多个会话互相不影响
事件循环
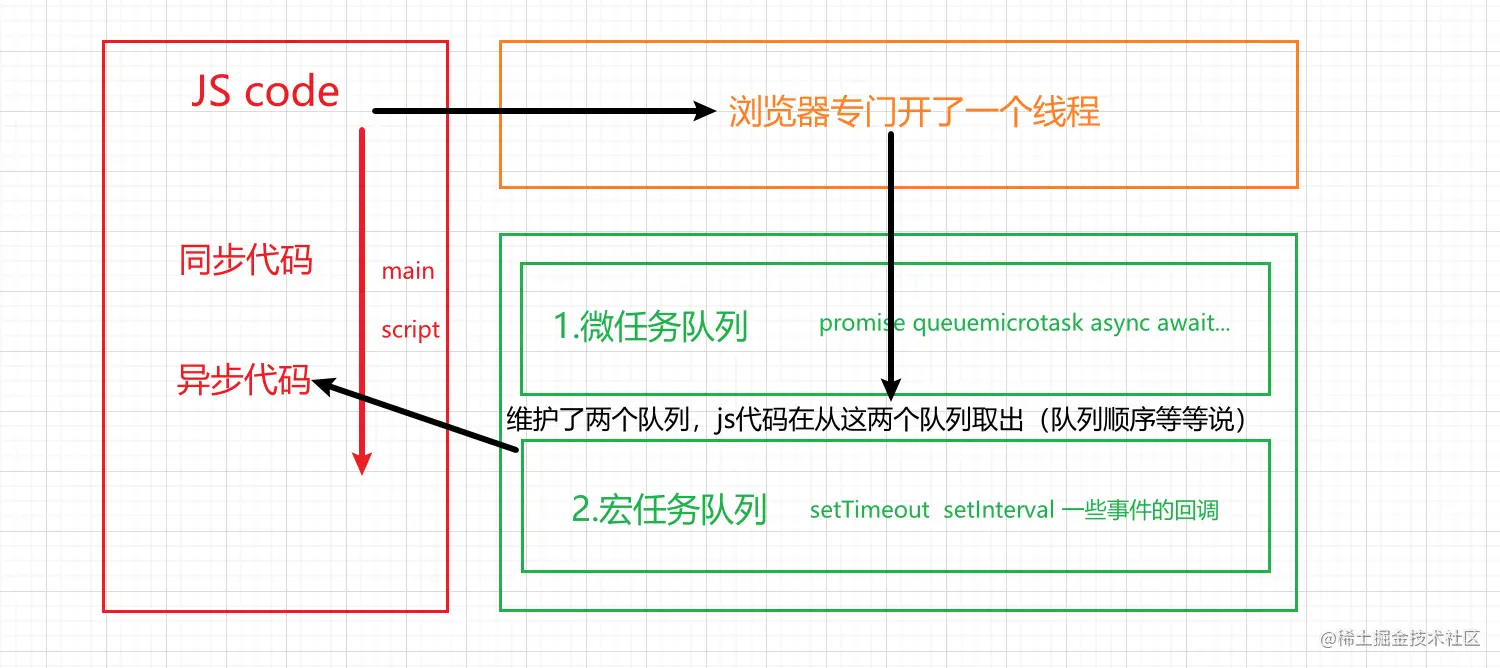
首先js代码先执行主线程的代码,也就是同步的代码,从上至下,遇到异步代码交给浏览器,浏览器专门开了一个线程,其中浏览器线程中维护这两个队列,一个微任务队列,一个宏任务队列。
宏任务队列 Macrotask Queue: ajax、setTimeout、setInterval、Dom监听等
微任务队列 Microtask Queue: Promise的then回调、 Mutation Observer API、queueMicrotask
注意:每一次执行宏任务之前,都是要确保我微任务的队列是空的,也就是说从代码执行的顺序来说微任务优先于宏任务。
但是存在插队的情况,也就是说当我微任务执行完了,要开始执行宏任务了(有多个宏任务),宏任务队列当队列中的代码执行了,宏任务队列里面又有微任务代码,又把微任务放入到微任务队列当中。
此时特别注意!!!从严格的意义来说,紧接着是先进行编译的宏任务,但是此时微任务里面有任务,才去执行的微任务队列,而不是直接去执行的。这些异步的代码交给js执行,这样三者形成了一个闭环,我们称之为事件循环。
流程运行控制引擎
元素执行控制
任务循环机制
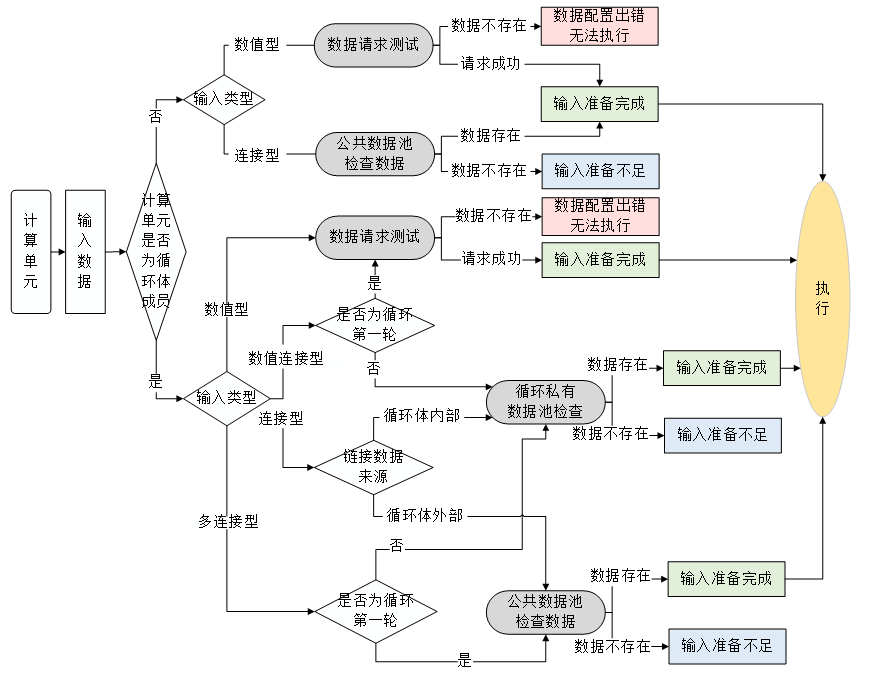
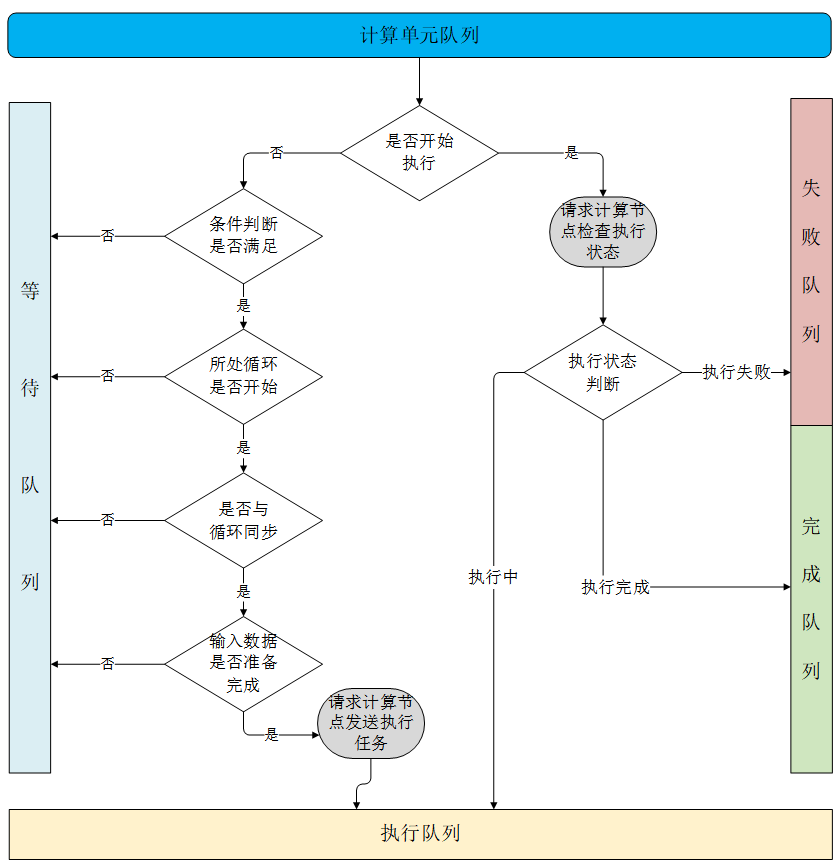
借鉴chrome v8等浏览器引擎事件循环(Event Loop)的成熟策略,设计了基于任务循环(Task Loop)的流程运行并发模型和运转控制策略。Task Loop维护一个运行控制线程,核心是队列维护方法query。query维护四个队列,分别对应等待队列waiting list、执行队列running list、完成队列completed list和失败队列failedList,通过对元素进行遍历处理检查状态,并分别压入对应的队列。等待队列中的元素检查数据是否完备、执行条件是否满足,满足则执行;执行队列中的元素向计算节点请求更新状态;完成队列和失败队列则根据各自情况更新输出数据和状态。TaskLoop不断循环,从而检查各个元素状态并更新qurey队列,将条件满足的元素压入执行。而在容错方面,设计了错误滞后策略即多次运行失败认定失败来减小错误影响。
通过这种控制方法,各个满足执行前提条件的元素可以互不干涉、并发执行,同时将元素的依赖关系和流程的逻辑结构映射为元素的执行条件和数据准备情况,可以满足流程运行控制的要求的前题下简化程序结构、解耦各部分的功能。
流程说明
(1)每个工作流开辟一个单独的线程不断循环计算(Task Loop)
(2)每一次循环都遍历等待队列waiting list的所有计算单元,判断其数据是否已经准备完毕(前面步骤是否已经执行完),如果准备完毕则将该计算单元作为任务加入到执行队列running list中,并开始计算(调用服务)
(3)输入数据的类型分为两种,一种是直接输入(value),一种是前面的流程结果(link),所以在设置输入数据的属性的时候需要根据类型从不同的来源获取到对应的值
(4)需要迭代的计算单元,对于为link(前面的流程结果)的输入数据,需要重新计算前面流程结果,所以需把关联的计算单元也加入到等待队列waiting list中
(5)对于条件判断(分支和循环),根据条件的成立与否(true/false)将下一个计算单元加入到等待队列waiting list中
(6)每个计算单元计算完成后,根据计算状态将计算单元加入到完成队列completed list或失败队列failedList中,输出数据需加入到数据共享池SharedData中,以便后续计算单元从池中获取到前面的计算结果。对于迭代模型,当还未到达最大迭代次数的时候会将当前计算单元重新加入等待队列,同时创建一个临时文件池TempOutput(独立于SharedData),记录最新的运算结果
(7)当等待队列waiting list以及执行队列running list中没有计算任务时,整个工作流流程结束
工作流功能实现
工作空间
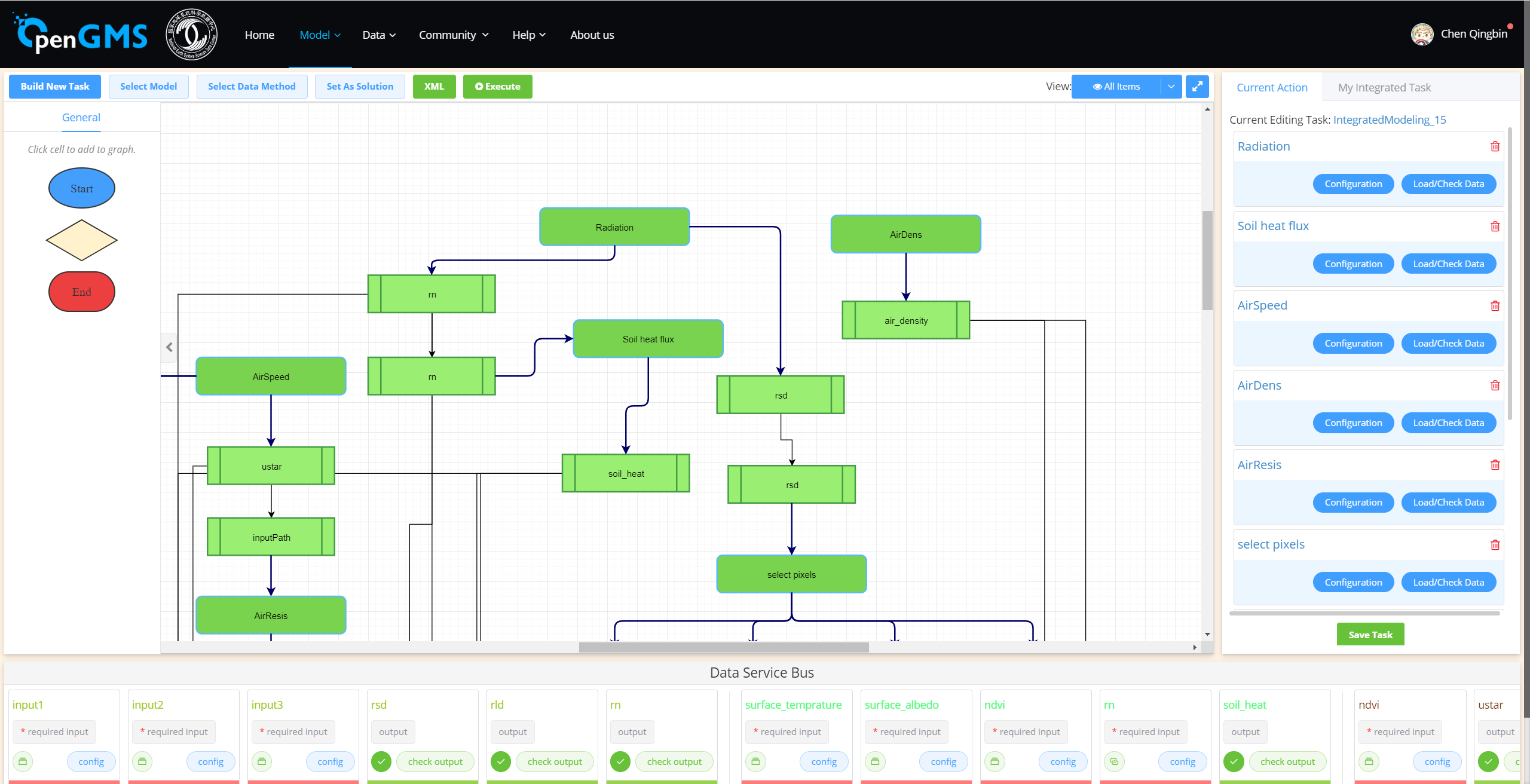
工作流详情
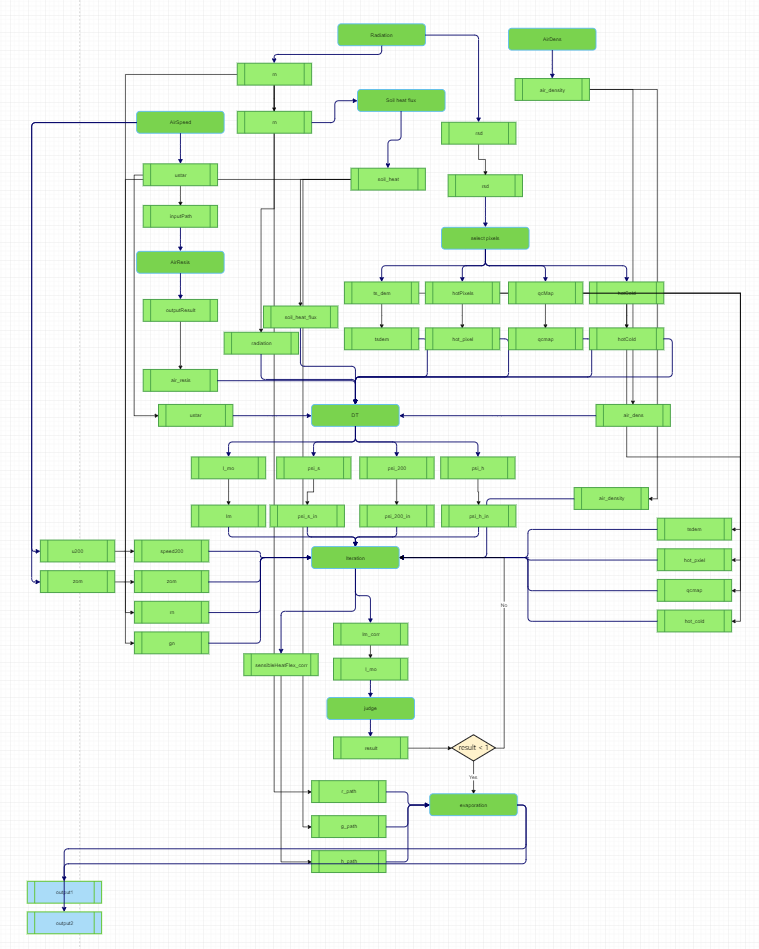
后端关键代码
Service
|
|
TaskLoopHandler
|
|
TaskLoop
|
|
前端关键代码
前端使用mxGraph实现