简单工厂模式——计算器#
结构图#
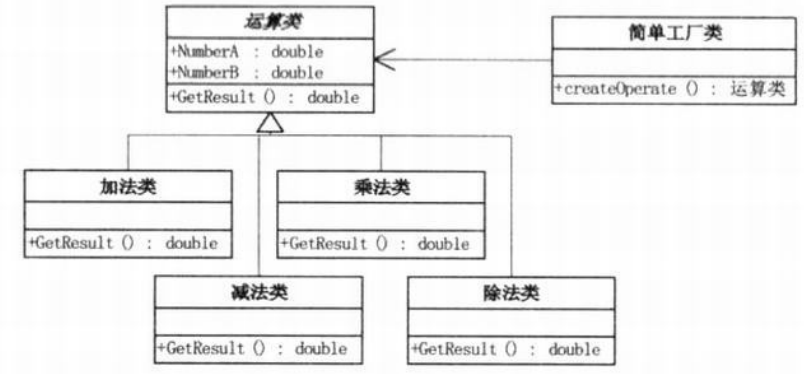
简单工厂模式实现#
运算接口(父类)
1
2
3
|
public interface IOperation {
double getResult(double a, double b);
}
|
创建两个运算符类实现该接口
1
2
3
4
5
6
7
8
|
public class AddOperation implements IOperation {
@Override
public double getResult(double a, double b) {
return a + b;
}
}
|
1
2
3
4
5
6
7
8
|
public class MultiOperation implements IOperation{
@Override
public double getResult(double a, double b) {
return a * b;
}
}
|
工厂类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public class OperationFactory {
public IOperation createOperate(String operate){
IOperation operation = null;
switch (operate){
case "add":{
operation = new AddOperation();
break;
}
case "multi":{
operation = new MultiOperation();
break;
}
}
return operation;
}
}
|
主函数
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public class Calculator {
public static void main(String[] args) {
System.out.println(Calculator.test("add",1,2));
System.out.println(Calculator.test("multi",1,2));
}
public static double test(String op, double a, double b){
OperationFactory factory = new OperationFactory();
return factory.createOperate(op).getResult(a,b);
}
}
|
之后需要更改算法运算,只需更改相应的类即可。若是需要增加其他运算,秩序增加相应的运算子类,并且在工厂类添加新的分支即可。
工厂方法模式——计算器改进#
简单工厂模式的最大优点在于工厂类中包含了必要的逻辑判断,根据客户端的选择条件动态实例化相关的类,对于客户端来说,去除了与具体产品的依赖。就像计算器,让客户端不用管该用哪个类的实例,只需要把“+”给工厂,工厂自动就给出了相应的实例,客户端只要去做运算就可以了,不同的实例会实现不同的运算。但问题是,如果要加一个“求M数的N次方”的功能,我们是一定需要给运算工厂类的方法里加“Case”的分支条件的,修改原有的类,这就等于说,不但对扩展开放了,对修改也开放了,这样就违背了开放-封闭原则,于是工厂方法就来了。
工厂方法模式(Factory Method),定义一个用于创建对象的接口,让子类决定实例化哪个类。工厂方法使一个类的实例化延迟到其子类。
根据依赖倒转原则,把工厂类抽象出一个接口,这个接口只有一个方法,就是创建抽象产品的工厂方法。然后,所有的要生产具体类的工厂去实现这个接口,这样,一个简单工厂模式的工厂类,变成了一个工厂抽象接口和多个具体生成对象的工厂。要增加“求M数的N次方”的功能时,就不需要更改原有的工厂类了,只需要增加此功能的运算类和相应的工厂类就可以了。
结构图#
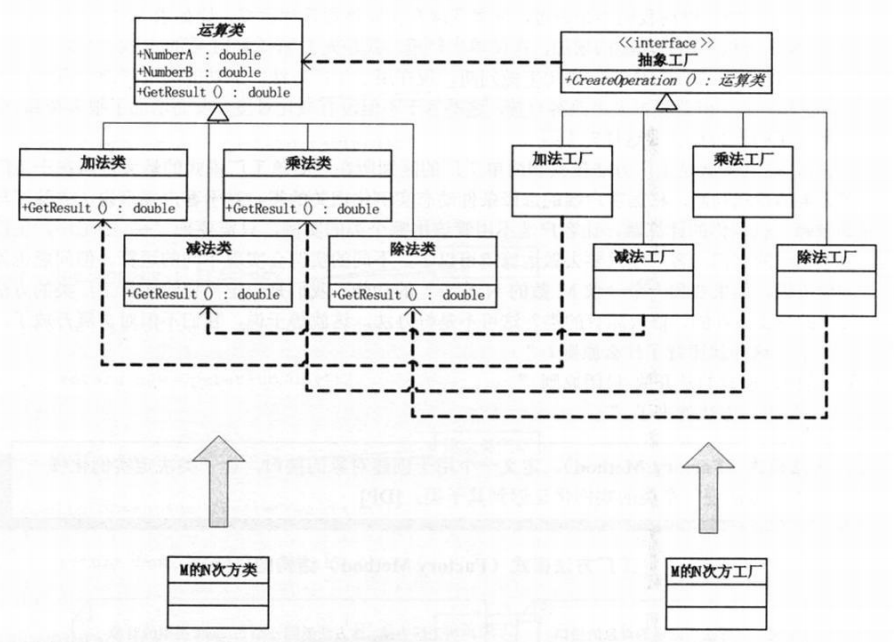
工厂方法模式实现#
抽象工厂
1
2
3
|
public interface IFactory {
IOperation createOperation();
}
|
工厂具体实现类
1
2
3
4
5
6
|
public class AddOpFactory implements IFactory{
@Override
public IOperation createOperation() {
return new AddOperation();
}
}
|
1
2
3
4
5
6
|
public class MultiOpFactory implements IFactory{
@Override
public IOperation createOperation() {
return new MultiOperation();
}
}
|
运算类
1
2
3
|
public interface IOperation {
double getResult(double a, double b);
}
|
运算具体实现类
1
2
3
4
5
6
|
public class AddOperation implements IOperation {
@Override
public double getResult(double a, double b) {
return a + b;
}
}
|
1
2
3
4
5
6
|
public class MultiOperation implements IOperation {
@Override
public double getResult(double a, double b) {
return a * b;
}
}
|
主函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public class FactoryMethodTest {
public static void main(String[] args) {
System.out.println(test("add", 1, 2));
System.out.println(test("multi", 1, 2));
}
public static double test(String op, double a, double b){
IOperation operation = null;
switch (op){
case "add":{
operation = (new AddOpFactory()).createOperation();
break;
}
case "multi":{
operation = (new MultiOpFactory()).createOperation();
break;
}
}
return operation.getResult(a,b);
}
}
|
抽象工厂模式——访问数据库#
抽象工厂模式(Abstract Factory),提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
结构图#
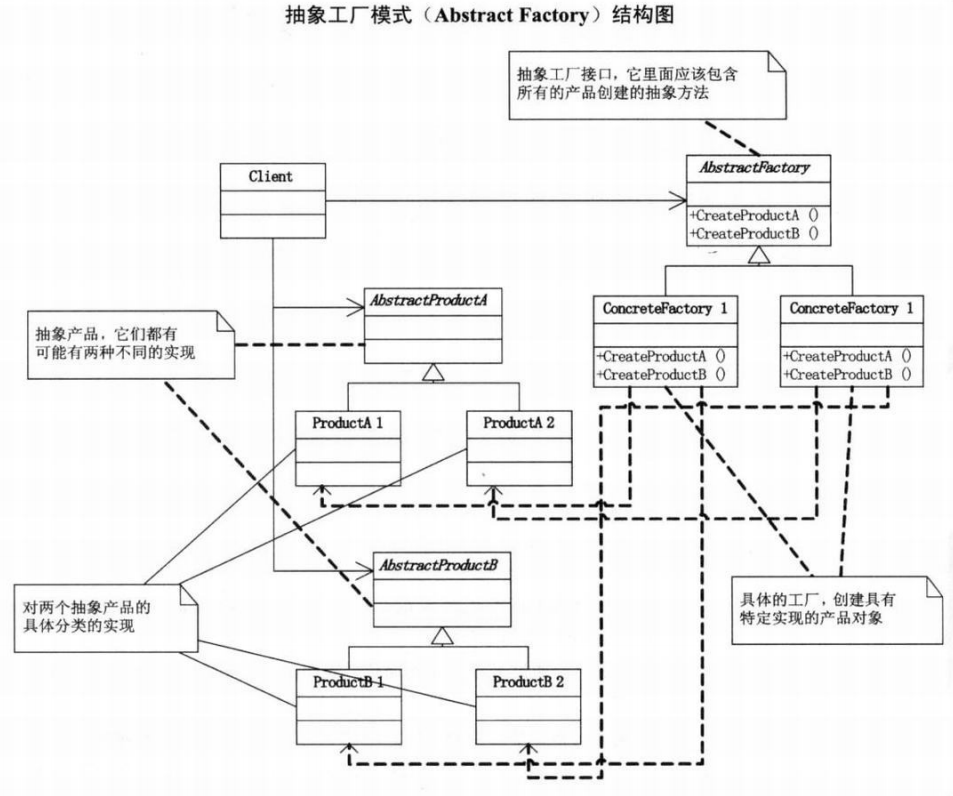
AbstractProductA和AbstractProductB是两个抽象产品,之所以为抽象,是因为它们都有可能有两种不同的实现,拿例子来说就是User和Department,而 ProductA1、ProductA2和ProductB1、ProductB2 就是对两个抽象产品的具体分类的实现,比如 ProductA1可以理解为是SqlserverUser,而ProductB1是AccessUser。
**IFactory是一个抽象工厂接口,它里面应该包含所有的产品创建的抽象方法。而ConcreteFactory1和ConcreteFactory2就是具体的工厂了。**就像SqlserverFactory和 AccessFactory一样。
通常是在运行时刻再创建一个ConcreteFactory类的实例,这个具体的工厂再创建具有特定实现的产品对象,也就是说,为创建不同的产品对象,客户端应使用不同的具体工厂。
用反射+抽象工厂实现数据访问#
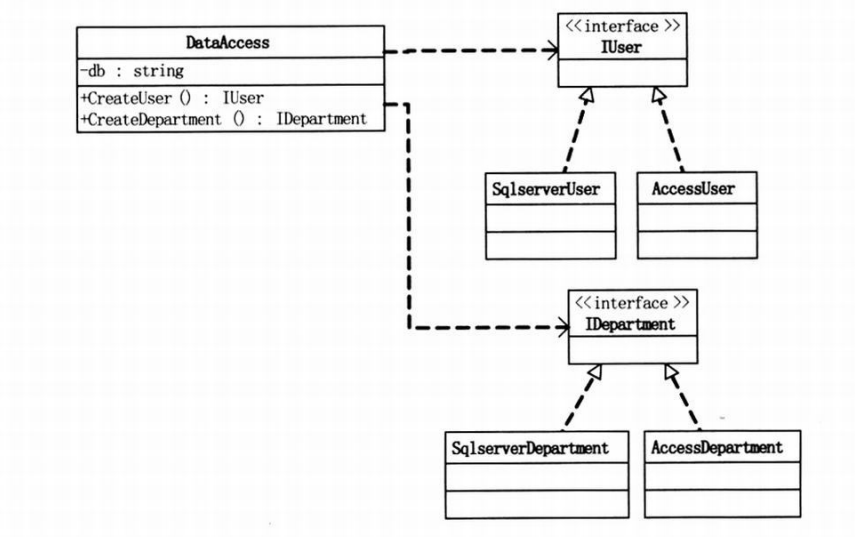
DataAccess类,用反射技术,取代IFactory、SqlserverFactory和 AccessFactory。
代码实现#
IUser
1
2
3
4
|
public interface IUser {
void insert(User user);
void get(String id);
}
|
IDepartment
1
2
3
4
|
public interface IDepartment {
void insert(Department department);
void get(String id);
}
|
SqlserverUser
1
2
3
4
5
6
7
8
9
10
11
|
public class SqlserverUser implements IUser{
@Override
public void insert(User user) {
System.out.println("sqlserver user insert");
}
@Override
public void get(String id) {
System.out.println("sqlserver user get");
}
}
|
MongoDBUser
1
2
3
4
5
6
7
8
9
10
11
|
public class MongoDBUser implements IUser{
@Override
public void insert(User user) {
System.out.println("MongoDB user insert");
}
@Override
public void get(String id) {
System.out.println("MongoDB user get");
}
}
|
SqlserverDepartment
1
2
3
4
5
6
7
8
9
10
11
|
public class SqlserverDepartment implements IDepartment{
@Override
public void insert(Department department) {
System.out.println("sqlserver department insert");
}
@Override
public void get(String id) {
System.out.println("sqlserver department get");
}
}
|
MongoDBDepartment
1
2
3
4
5
6
7
8
9
10
11
|
public class MongoDBDepartment implements IDepartment{
@Override
public void insert(Department department) {
System.out.println("MongoDB department insert");
}
@Override
public void get(String id) {
System.out.println("MongoDB department get");
}
}
|
DataAccess
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public class DBAccess {
private String db;
public IUser createUser() throws ClassNotFoundException, InstantiationException, IllegalAccessException {
//反射 Class.forName("test.bin.abstractFactory.MongoDBUser")
return (IUser) Class.forName("test.bin.abstractFactory." + db + "User").newInstance();
}
public IDepartment createDepartment() throws ClassNotFoundException, InstantiationException, IllegalAccessException{
return (IDepartment) Class.forName("test.bin.abstractFactory." + db + "Department").newInstance();
}
public void setDb(String db) {
this.db = db;
}
}
|
main
1
2
3
4
5
6
7
8
9
10
|
public class AbstractFactory {
public static void main(String[] args) throws ClassNotFoundException, InstantiationException, IllegalAccessException {
DBAccess dbAccess = new DBAccess();
dbAccess.setDb("Sqlserver");
IUser user = dbAccess.createUser();
IDepartment department = dbAccess.createDepartment();
user.get("1");
department.get("1");
}
}
|
通过配置文件读取配置#
db.properties
main
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public class AbstractFactory {
public static void main(String[] args) throws ClassNotFoundException, InstantiationException, IllegalAccessException, IOException {
//通过配置文件读取访问的数据库
Properties properties = new Properties();
ClassLoader classLoader = AbstractFactory.class.getClassLoader();
// 使用FileInputStream读取配置文件,文件默认在当前的module下
// FileInputStream fis = new FileInputStream("src\\test\\bin\\abstractFactory\\db.properties");
// 使用ClassLoader读取配置文件,配置文件默认识别为:当前module的src下
InputStream is = classLoader.getResourceAsStream("test\\bin\\abstractFactory\\db.properties");
properties.load(is);
String db = properties.getProperty("db");
DBAccess dbAccess = new DBAccess();
dbAccess.setDb(db);
IUser user = dbAccess.createUser();
IDepartment department = dbAccess.createDepartment();
user.get("1");
department.get("1");
}
}
|
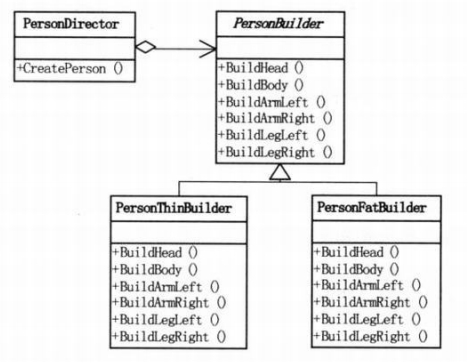
建造者模式——创建小人#
建造者模式(Builder),将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
建造者模式实现#
PersonBuilder
1
2
3
4
5
6
|
public interface PersonBuilder {
void buildHead();
void buildArms();
void buildBody();
void buildLegs();
}
|
PersonConcrete
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public class PersonOneBuilder implements PersonBuilder{
@Override
public void buildHead() {
System.out.println("buildHead 1");
}
@Override
public void buildArms() {
System.out.println("buildArms 1");
}
@Override
public void buildBody() {
System.out.println("buildBody 1");
}
@Override
public void buildLegs() {
System.out.println("buildLegs 1");
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public class PersonTwoBuilder implements PersonBuilder{
@Override
public void buildHead() {
System.out.println("buildHead 2");
}
@Override
public void buildArms() {
System.out.println("buildArms 2");
}
@Override
public void buildBody() {
System.out.println("buildBody 2");
}
@Override
public void buildLegs() {
System.out.println("buildLegs 2");
}
}
|
PersonDirector
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public class Director {
private PersonBuilder personBuilder;
public Director(PersonBuilder personBuilder) {
this.personBuilder = personBuilder;
}
public void build(){
personBuilder.buildHead();
personBuilder.buildBody();
personBuilder.buildArms();
personBuilder.buildLegs();
}
}
|
main
1
2
3
4
5
6
7
8
|
public class Test {
public static void main(String[] args) {
Director directorOne = new Director(new PersonOneBuilder());
Director directorTwo = new Director(new PersonTwoBuilder());
directorOne.build();
directorTwo.build();
}
}
|
建造者模式解析#
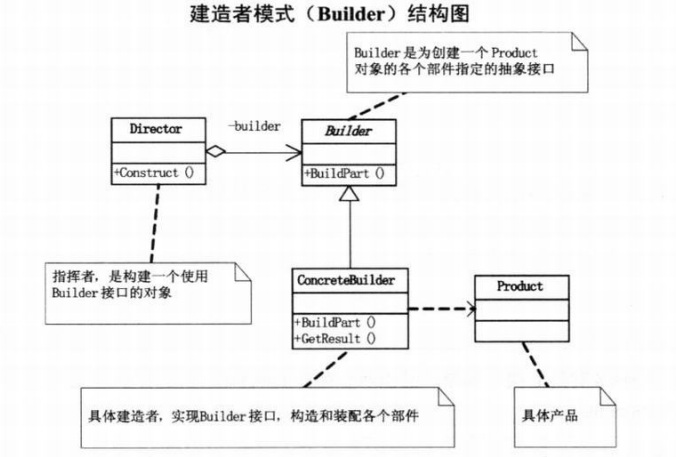
Builder是为创建一个 Product对象的各个部件指定的抽象接口。
ConcreteBuilder是具体建造者,实现 Builder 接口,构造和装配各个部件。
Product是具体的产品角色。
Director是指挥者,构建一个使用Builder接口的对象,用来根据用户的需求构建Product。
何时使用建造者模式#
主要是用于创建一些复杂的对象,这些对象内部构建间的建造顺序通常是稳定的,但对象内部的构建通常面临着复杂的变化。
建造者模式的好处就是使得建造代码与表示代码分离,由于建造者隐藏了该产品是如何组装的,所以若需要改变一个产品的内部表示,只需要再定义一个具体的建造者就可以了。
代码改造#
Product
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public class Person {
List<String> parts = new ArrayList<>();
public void add(String part){
parts.add(part);
}
@Override
public String toString() {
return "Person{" +
"parts=" + parts +
'}';
}
}
|
Builder
1
2
3
4
5
6
|
public interface PersonBuilder {
void buildHead();
void buildArms();
void buildBody();
void buildLegs();
}
|
ConcreteBuilder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public class PersonOneBuilder implements PersonBuilder{
private Person person = new Person();
@Override
public void buildHead() {
person.add("buildHead 1");
}
@Override
public void buildArms() {
person.add("buildArms 1");
}
@Override
public void buildBody() {
person.add("buildBody 1");
}
@Override
public void buildLegs() {
person.add("buildLegs 1");
}
public Person getPerson() {
return person;
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public class PersonTwoBuilder implements PersonBuilder{
private Person person = new Person();
@Override
public void buildHead() {
person.add("buildHead 2");
}
@Override
public void buildArms() {
person.add("buildArms 2");
}
@Override
public void buildBody() {
person.add("buildBody 2");
}
@Override
public void buildLegs() {
person.add("buildLegs 2");
}
public Person getPerson() {
return person;
}
}
|
Derector
1
2
3
4
5
6
7
8
9
|
public class Director {
public void construct(PersonBuilder personBuilder) {
personBuilder.buildHead();
personBuilder.buildBody();
personBuilder.buildArms();
personBuilder.buildLegs();
}
}
|
main
1
2
3
4
5
6
7
8
9
10
11
|
public class Test {
public static void main(String[] args) {
PersonOneBuilder personOneBuilder = new PersonOneBuilder();
PersonTwoBuilder personTwoBuilder = new PersonTwoBuilder();
Director director = new Director();
director.construct(personOneBuilder);
director.construct(personTwoBuilder);
System.out.println(personOneBuilder.getPerson());
System.out.println(personTwoBuilder.getPerson());
}
}
|
原型模式——简历复印#
原型模式(Prototype),用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
原型模式其实就是从一个对象再创建另外一个可定制的对象,而且不需知道任何创建的细节
结构图#
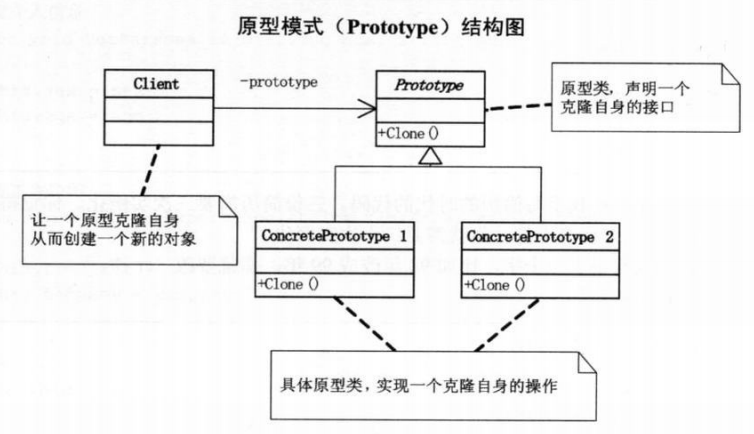
实现对象拷贝(浅拷贝)的类,需要实现 Cloneable 接口,并重写 clone() 方法
原型模式实现#
简历类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public class Resume implements Cloneable{
private String name;
private int age;
private Company company;
@Override
public Resume clone() {
try {
Resume clone = (Resume) super.clone();
return clone;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
... // get set toString
}
|
公司类
1
2
3
4
5
6
|
public class Company {
private String name;
private String address;
... // get set toString
}
|
主函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public class PrototypeTest {
public static void main(String[] args) throws CloneNotSupportedException {
Resume resume = new Resume("张三", 18);
Company company = new Company("字节","eimeng");
resume.setCompany(company);
Resume resume1 = resume.clone();
resume1.setAge(19);
Resume resume2 = resume.clone();
resume.setName("李四");
resume.setAge(20);
company.setName("高德");
System.out.println(resume);
System.out.println(resume1);
System.out.println(resume2);
//Resume{name='李四', age=20, company=Company{name='高德', address='eimeng'}}
//Resume{name='张三', age=19, company=Company{name='高德', address='eimeng'}}
//Resume{name='张三', age=18, company=Company{name='高德', address='eimeng'}}
}
}
|
从上面的日志中可以发现,在拷贝过后,更改resume的name和age时,拷贝的resume1和resume2相应字段没有发生改变,但是更改company对象的name属性时三个实例的company都变成了最后一次设置的值,这是为什么呢?这其实是因为浅拷贝和深拷贝的原因。
浅拷贝和深拷贝#
https://www.jianshu.com/p/94dbef2de298
https://www.cnblogs.com/shakinghead/p/7651502.html
浅拷贝#
浅拷贝是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。即默认拷贝构造函数只是对对象进行浅拷贝复制(逐个成员依次拷贝),即只复制对象空间而不复制资源。
浅拷贝特点
(1) 对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个。
(2) 对于引用类型,比如数组或者类对象,因为引用类型是引用传递,所以浅拷贝只是把内存地址赋值给了成员变量,它们指向了同一内存空间。改变其中一个,会对另外一个也产生影响。
分析打印结果
基本数据类型是值传递,所以修改值后不会影响另一个对象的该属性值;
引用数据类型是地址传递(引用传递),所以修改值后另一个对象的该属性值会同步被修改。
String类型非常特殊,首先,String类型属于引用数据类型,不属于基本数据类型,但是String类型的数据是存放在常量池中的,也就是无法修改的!也就是说,当我将name属性从“张三”改为“李四"后,并不是修改了这个数据的值,而是把这个数据的引用从指向”张三“这个常量改为了指向”李四“这个常量。在这种情况下,另一个对象的name属性值仍然指向”张三“不会受到影响。
通过上面的例子可以看到,浅拷贝会带来数据安全方面的隐患,例如只是想修改 resume 的 company,但是另外两个实例的 company 也被修改了,因为它们都是指向的同一个地址。所以,此种情况下,需要用到深拷贝。
深拷贝#
首先介绍对象图的概念。设想一下,一个类有一个对象,其成员变量中又有一个对象,该对象指向另一个对象,另一个对象又指向另一个对象,直到一个确定的实例。这就形成了对象图。那么,对于深拷贝来说,不仅要复制对象的所有基本数据类型的成员变量值,还要为所有引用数据类型的成员变量申请存储空间,并复制每个引用数据类型成员变量所引用的对象,直到该对象可达的所有对象。也就是说,对象进行深拷贝要对整个对象图进行拷贝!
简单地说,深拷贝对引用数据类型的成员变量的对象图中所有的对象都开辟了内存空间;而浅拷贝只是传递地址指向,新的对象并没有对引用数据类型创建内存空间。
因为创建内存空间和拷贝整个对象图,所以深拷贝相比于浅拷贝速度较慢并且花销较大。
深拷贝的实现方法主要有两种:
一、通过重写clone方法来实现深拷贝
与通过重写clone方法实现浅拷贝的基本思路一样,只需要为对象图的每一层的每一个对象都实现Cloneable接口并重写clone方法,最后在最顶层的类的重写的clone方法中调用所有的clone方法即可实现深拷贝。简单的说就是:每一层的每个对象都进行浅拷贝=深拷贝。
简历类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public class Resume implements Cloneable{
private String name;
private int age;
private Company company;
@Override
public Resume clone() {
try {
Resume clone = (Resume) super.clone();
// 简历类实例的company对象属性,调用其clone方法进行拷贝
clone.company = clone.getCompany().clone();
return clone;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
... // get set toString
}
|
公司类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public class Company {
private String name;
private String address;
@Override
public Company clone() implements Cloneable{
try {
return (Company) super.clone();
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
... // get set toString
}
|
主函数
1
2
3
4
5
6
7
8
|
//主函数不变
//输出结果如下
System.out.println(resume);
System.out.println(resume1);
System.out.println(resume2);
// Resume{name='李四', age=20, company=Company{name='高德', address='eimeng'}}
// Resume{name='张三', age=19, company=Company{name='字节', address='eimeng'}}
// Resume{name='张三', age=18, company=Company{name='字节', address='eimeng'}}
|
进行了深拷贝之后,无论是什么类型的属性值的修改,都不会影响另一个对象的属性值。
二、通过对象序列化实现深拷贝
虽然层次调用clone方法可以实现深拷贝,但是显然代码量实在太大。特别对于属性数量比较多、层次比较深的类而言,每个类都要重写clone方法太过繁琐。
将对象序列化为字节序列后,默认会将该对象的整个对象图进行序列化,再通过反序列即可完美地实现深拷贝。
简历类
1
2
3
4
5
6
7
|
public class ResumeSerializable implements Serializable {
private String name;
private int age;
private CompanySerializable company;
... // get set toString
}
|
公司类
1
2
3
4
5
6
|
public class CompanySerializable implements Serializable {
private String name;
private String address;
... // get set toString
}
|
测试类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public static void test2() throws IOException, ClassNotFoundException {
ResumeSerializable resume = new ResumeSerializable("张三", 18);
CompanySerializable company = new CompanySerializable("字节","eimeng");
resume.setCompany(company);
//通过序列化方法实现深拷贝
ByteArrayOutputStream bos=new ByteArrayOutputStream();
ObjectOutputStream oos=new ObjectOutputStream(bos);
oos.writeObject(resume);
oos.flush();
ObjectInputStream ois=new ObjectInputStream(new ByteArrayInputStream(bos.toByteArray()));
ResumeSerializable resume1=(ResumeSerializable)ois.readObject();
resume1.setAge(19);
resume.setName("李四");
resume.setAge(20);
company.setName("高德");
System.out.println(resume);
System.out.println(resume1);
// Resume{name='李四', age=20, company=Company{name='高德', address='eimeng'}}
// Resume{name='张三', age=19, company=Company{name='字节', address='eimeng'}}
}
|
单例模式——生娃#
单例模式(Singleton),保证一个类仅有一个实例,并提供一个访问它的全局访问点。
通常我们可以让一个全局变量使得一个对象被访问,但它不能防止你实例化多个对象。一个最好的办法就是,让类自身负责保存它的唯一实例。这个类可以保证没有其他实例可以被创建,并且它可以提供一个访问该实例的方法。

应用场景#
网站的计数器,一般也是单例模式实现,否则难以同步。
应用程序的日志应用,一般都使用单例模式实现,这一般是由于共享的日志文件一直处于打开状态,因为只能有一个实例去操作,否则内容不好追加。数据库连接池的设计一般也是采用单例模式,因为数据库连接是一种数据库资源。
项目中,读取配置文件的类,一般也只有一个对象。没有必要每次使用配置文件数据,都生成一个对象去读取。
Application 也是单例的典型应用
Windows的Task Manager (任务管理器)就是很典型的单例模式
Windows的Recycle Bin(回收站)也是典型的单例应用。在整个系统运行过程中,回收站一直维护着仅有的一个实例。
代码实现#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
/*
* 单例设计模式:
* 1. 所谓类的单例设计模式,就是采取一定的方法保证在整个的软件系统中,对某个类只能存在一个对象实例。
*
* 2. 如何实现?
* 饿汉式 vs 懒汉式
*
* 3. 区分饿汉式 和 懒汉式
* 饿汉式:
* 坏处:对象加载时间过长。
* 好处:饿汉式是线程安全的
*
* 懒汉式:好处:延迟对象的创建。
* 目前的写法坏处:线程不安全。--->到多线程内容时,再修改
*
*/
public class SingletonTest1 {
public static void main(String[] args) {
// Bank bank1 = new Bank();
// Bank bank2 = new Bank();
Bank bank1 = Bank.getInstance();
Bank bank2 = Bank.getInstance();
System.out.println(bank1 == bank2);
}
}
//饿汉式
class Bank{
//1.私有化类的构造器
private Bank(){
}
//2.内部创建类的对象
//4.要求此对象也必须声明为静态的
private static Bank instance = new Bank();
//3.提供公共的静态的方法,返回类的对象
public static Bank getInstance(){
return instance;
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
/*
* 单例模式的懒汉式实现
*
*/
public class SingletonTest2 {
public static void main(String[] args) {
Order order1 = Order.getInstance();
Order order2 = Order.getInstance();
System.out.println(order1 == order2);
}
}
class Order{
//1.私有化类的构造器
private Order(){
}
//2.声明当前类对象,没有初始化
//4.此对象也必须声明为static的
private static Order instance = null;
//3.声明public、static的返回当前类对象的方法
public static Order getInstance(){
if(instance == null){
instance = new Order();
}
return instance;
}
}
|
使用同步机制将单例模式中的懒汉式改写为线程安全的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
class Bank{
private Bank(){}
private static Bank instance = null;
public static Bank getInstance(){
//方式一:效率稍差
// synchronized (Bank.class) {
// if(instance == null){
//
// instance = new Bank();
// }
// return instance;
// }
//方式二:效率更高
if(instance == null){
synchronized (Bank.class) {
if(instance == null){
instance = new Bank();
}
}
}
return instance;
}
}
|