1. 实验目的
- 建立对系统调用接口的深入认识;
- 掌握系统调用的基本过程;
- 能完成系统调用的全面控制;
- 为后续实验做准备。
2. 实验内容
此次实验的基本内容是:在 Linux 0.11 上添加两个系统调用,并编写两个简单的应用程序测试它们。
(1)iam()
第一个系统调用是 iam(),其原型为:
|
|
完成的功能是将字符串参数 name 的内容拷贝到内核中保存下来。要求 name 的长度不能超过 23 个字符。返回值是拷贝的字符数。如果 name 的字符个数超过了 23,则返回 “-1”,并置 errno 为 EINVAL。
在 kernal/who.c 中实现此系统调用。
(2)whoami()
第二个系统调用是 whoami(),其原型为:
|
|
它将内核中由 iam() 保存的名字拷贝到 name 指向的用户地址空间中,同时确保不会对 name 越界访存(name 的大小由 size 说明)。返回值是拷贝的字符数。如果 size 小于需要的空间,则返回“-1”,并置 errno 为 EINVAL。
也是在 kernal/who.c 中实现。
(3)测试程序
运行添加过新系统调用的 Linux 0.11,在其环境下编写两个测试程序 iam.c 和 whoami.c。最终的运行结果是:
|
|
3. 实验报告
在实验报告中回答如下问题:
- 从 Linux 0.11 现在的机制看,它的系统调用最多能传递几个参数?你能想出办法来扩大这个限制吗?
- 用文字简要描述向 Linux 0.11 添加一个系统调用 foo() 的步骤。
4. 实验提示
首先,请将 Linux 0.11 的源代码恢复到原始状态。
|
|
操作系统实现系统调用的基本过程(在 MOOC 课程中已经给出了详细的讲解)是:
- 应用程序调用库函数(API);
- API 将系统调用号存入 EAX,然后通过中断调用使系统进入内核态;
- 内核中的中断处理函数根据系统调用号,调用对应的内核函数(系统调用);
- 系统调用完成相应功能,将返回值存入 EAX,返回到中断处理函数;
- 中断处理函数返回到 API 中;
- API 将 EAX 返回给应用程序。
4.1 应用程序如何调用系统调用
在通常情况下,调用系统调用和调用一个普通的自定义函数在代码上并没有什么区别,但调用后发生的事情有很大不同。
调用自定义函数是通过 call 指令直接跳转到该函数的地址,继续运行。
而调用系统调用,是调用系统库中为该系统调用编写的一个接口函数,叫 API(Application Programming Interface)。API 并不能完成系统调用的真正功能,它要做的是去调用真正的系统调用,过程是:
- 把系统调用的编号存入 EAX;
- 把函数参数存入其它通用寄存器;
- 触发 0x80 号中断(int 0x80)。
linux-0.11 的 lib 目录下有一些已经实现的 API。Linus 编写它们的原因是在内核加载完毕后,会切换到用户模式下,做一些初始化工作,然后启动 shell。而用户模式下的很多工作需要依赖一些系统调用才能完成,因此在内核中实现了这些系统调用的 API。
后面的目录如果没有特殊说明,都是指在
/home/shiyanlou/oslab/linux-0.11中。比如下面的lib/close.c,是指/home/shiyanlou/oslab/linux-0.11/lib/close.c。
我们不妨看看 lib/close.c,研究一下 close() 的 API:
|
|
其中 _syscall1 是一个宏,在 include/unistd.h 中定义。
|
|
将 _syscall1(int,close,int,fd) 进行宏展开,可以得到:
|
|
这就是 API 的定义。它先将宏 __NR_close 存入 EAX,将参数 fd 存入 EBX,然后进行 0x80 中断调用。调用返回后,从 EAX 取出返回值,存入 __res,再通过对 __res 的判断决定传给 API 的调用者什么样的返回值。
其中 __NR_close 就是系统调用的编号,在 include/unistd.h 中定义:
|
|
在 0.11 环境下编译 C 程序,包含的头文件都在 /usr/include 目录下。
该目录下的 unistd.h 是标准头文件(它和 0.11 源码树中的 unistd.h 并不是同一个文件,虽然内容可能相同),没有 __NR_whoami 和 __NR_iam 两个宏,需要手工加上它们,也可以直接从修改过的 0.11 源码树中拷贝新的 unistd.h 过来。
4.2 从“int 0x80”进入内核函数
int 0x80 触发后,接下来就是内核的中断处理了。先了解一下 0.11 处理 0x80 号中断的过程。
在内核初始化时,主函数(在 init/main.c 中,Linux 实验环境下是 main(),Windows 下因编译器兼容性问题被换名为 start())调用了 sched_init() 初始化函数:
|
|
sched_init() 在 kernel/sched.c 中定义为:
|
|
set_system_gate 是个宏,在 include/asm/system.h 中定义为:
|
|
_set_gate 的定义是:
|
|
虽然看起来挺麻烦,但实际上很简单,就是填写 IDT(中断描述符表),将 system_call 函数地址写到 0x80 对应的中断描述符中,也就是在中断 0x80 发生后,自动调用函数 system_call。具体细节请参考《注释》的第 4 章。
接下来看 system_call。该函数纯汇编打造,定义在 kernel/system_call.s 中:
|
|
system_call 用 .globl 修饰为其他函数可见。
Windows 实验环境下会看到它有一个下划线前缀,这是不同版本编译器的特质决定的,没有实质区别。
call sys_call_table(,%eax,4) 之前是一些压栈保护,修改段选择子为内核段,call sys_call_table(,%eax,4) 之后是看看是否需要重新调度,这些都与本实验没有直接关系,此处只关心 call sys_call_table(,%eax,4) 这一句。
根据汇编寻址方法它实际上是:call sys_call_table + 4 * %eax,其中 eax 中放的是系统调用号,即 __NR_xxxxxx。
显然,sys_call_table 一定是一个函数指针数组的起始地址,它定义在 include/linux/sys.h 中:
|
|
增加实验要求的系统调用,需要在这个函数表中增加两个函数引用 ——sys_iam 和 sys_whoami。当然该函数在 sys_call_table 数组中的位置必须和 __NR_xxxxxx 的值对应上。
同时还要仿照此文件中前面各个系统调用的写法,加上:
|
|
不然,编译会出错的。
4.3 实现 sys_iam() 和 sys_whoami()
添加系统调用的最后一步,是在内核中实现函数 sys_iam() 和 sys_whoami()。
每个系统调用都有一个 sys_xxxxxx() 与之对应,它们都是我们学习和模仿的好对象。
比如在 fs/open.c 中的 sys_close(int fd):
|
|
它没有什么特别的,都是实实在在地做 close() 该做的事情。
所以只要自己创建一个文件:kernel/who.c,然后实现两个函数就万事大吉了。
如果完全没有实现的思路,不必担心,本实验的 “6.7 在用户态和核心态之间传递数据” 还会有提示。
4.4 修改 Makefile
要想让我们添加的 kernel/who.c 可以和其它 Linux 代码编译链接到一起,必须要修改 Makefile 文件。
Makefile 里记录的是所有源程序文件的编译、链接规则,《注释》3.6 节有简略介绍。我们之所以简单地运行 make 就可以编译整个代码树,是因为 make 完全按照 Makefile 里的指示工作。
如果想要深入学习 Makefile,可以选择实验楼的课程: 《Makefile 基础教程》、《跟我一起来玩转 Makefile》。
Makefile 在代码树中有很多,分别负责不同模块的编译工作。我们要修改的是 kernel/Makefile。需要修改两处。
(1)第一处
|
|
改为:
|
|
添加了 who.o。
(2)第二处
|
|
改为:
|
|
添加了 who.s who.o: who.c ../include/linux/kernel.h ../include/unistd.h。
Makefile 修改后,和往常一样 make all 就能自动把 who.c 加入到内核中了。
如果编译时提示 who.c 有错误,就说明修改生效了。所以,有意或无意地制造一两个错误也不完全是坏事,至少能证明 Makefile 是对的。
4.5 用 printk() 调试内核
oslab 实验环境提供了基于 C 语言和汇编语言的两种调试手段。除此之外,适当地向屏幕输出一些程序运行状态的信息,也是一种很高效、便捷的调试方法,有时甚至是唯一的方法,被称为“printf 法”。
要知道到,printf() 是一个只能在用户模式下执行的函数,而系统调用是在内核模式中运行,所以 printf() 不可用,要用 printk()。
printk() 和 printf() 的接口和功能基本相同,只是代码上有一点点不同。printk() 需要特别处理一下 fs 寄存器,它是专用于用户模式的段寄存器。
看一看 printk 的代码(在 kernel/printk.c 中)就知道了:
|
|
显然,printk() 首先 push %fs 保存这个指向用户段的寄存器,在最后 pop %fs 将其恢复,printk() 的核心仍然是调用 tty_write()。查看 printf() 可以看到,它最终也要落实到这个函数上。
4.6 编写测试程序
激动地运行一下由你亲手修改过的 “Linux 0.11 pro++”!然后编写一个简单的应用程序进行测试。
比如在 sys_iam() 中向终端 printk() 一些信息,让应用程序调用 iam(),从结果可以看出系统调用是否被真的调用到了。
可以直接在 Linux 0.11 环境下用 vi 编写(别忘了经常执行“sync”以确保内存缓冲区的数据写入磁盘),也可以在 Ubuntu 或 Windows 下编完后再传到 Linux 0.11 下。无论如何,最终都必须在 Linux 0.11 下编译。编译命令是:
|
|
gcc 的 “-Wall” 参数是给出所有的编译警告信息,“-o” 参数指定生成的执行文件名是 iam,用下面命令运行它:
|
|
如果如愿输出了你的信息,就说明你添加的系统调用生效了。否则,就还要继续调试,祝你好运!
4.7 在用户态和核心态之间传递数据
指针参数传递的是应用程序所在地址空间的逻辑地址,在内核中如果直接访问这个地址,访问到的是内核空间中的数据,不会是用户空间的。所以这里还需要一点儿特殊工作,才能在内核中从用户空间得到数据。
要实现的两个系统调用参数中都有字符串指针,非常像 open(char *filename, ……),所以我们看一下 open() 系统调用是如何处理的。
|
|
可以看出,系统调用是用 eax、ebx、ecx、edx 寄存器来传递参数的。
- 其中 eax 传递了系统调用号,而 ebx、ecx、edx 是用来传递函数的参数的
- ebx 对应第一个参数,ecx 对应第二个参数,依此类推。
如 open 所传递的文件名指针是由 ebx 传递的,也即进入内核后,通过 ebx 取出文件名字符串。open 的 ebx 指向的数据在用户空间,而当前执行的是内核空间的代码,如何在用户态和核心态之间传递数据?
接下来我们继续看看 open 的处理:
|
|
由上面的代码可以看出,获取用户地址空间(用户数据段)中的数据依靠的就是段寄存器 fs,下面该转到 sys_open 执行了,在 fs/open.c 文件中:
|
|
它将参数传给了 open_namei()。
再沿着 open_namei() 继续查找,文件名先后又被传给dir_namei()、get_dir()。
在 get_dir() 中可以看到:
|
|
处理方法就很显然了:用 get_fs_byte() 获得一个字节的用户空间中的数据。
所以,在实现 iam() 时,调用 get_fs_byte() 即可。
但如何实现 whoami() 呢?即如何实现从核心态拷贝数据到用心态内存空间中呢?
猜一猜,是否有 put_fs_byte()?有!看一看 include/asm/segment.h :
|
|
他俩以及所有 put_fs_xxx() 和 get_fs_xxx() 都是用户空间和内核空间之间的桥梁,在后面的实验中还要经常用到。
4.8 运行脚本程序
Linux 的一大特色是可以编写功能强大的 shell 脚本,提高工作效率。本实验的部分评分工作由脚本 testlab2.sh 完成。它的功能是测试 iam.c 和 whoami.c。
首先将 iam.c 和 whoami.c 分别编译成 iam 和 whoami,然后将 testlab2.sh(在 /home/teacher 目录下) 拷贝到同一目录下。
用下面命令为此脚本增加执行权限:
|
|
然后运行之:
|
|
根据输出,可知 iam.c 和 whoami.c 的得分。
errno
errno 是一种传统的错误代码返回机制。
当一个函数调用出错时,通常会返回 -1 给调用者。但 -1 只能说明出错,不能说明错是什么。为解决此问题,全局变量 errno 登场了。错误值被存放到 errno 中,于是调用者就可以通过判断 errno 来决定如何应对错误了。
各种系统对 errno 的值的含义都有标准定义。Linux 下用“man errno”可以看到这些定义。
5. 实验步骤
1.添加宏定义
首先挂载文件系统,然后在此文件系统内进行编辑
挂载命令:sudo ./mount-hdc
首先找到unistd.h头文件,此文件在include子目录内
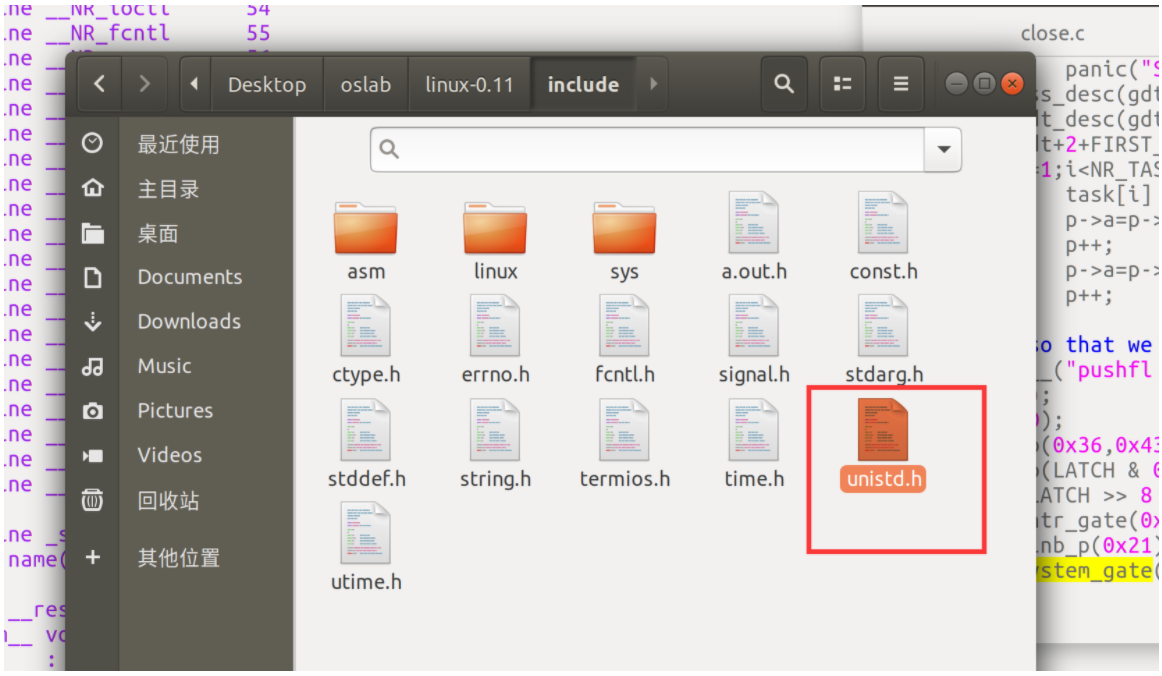
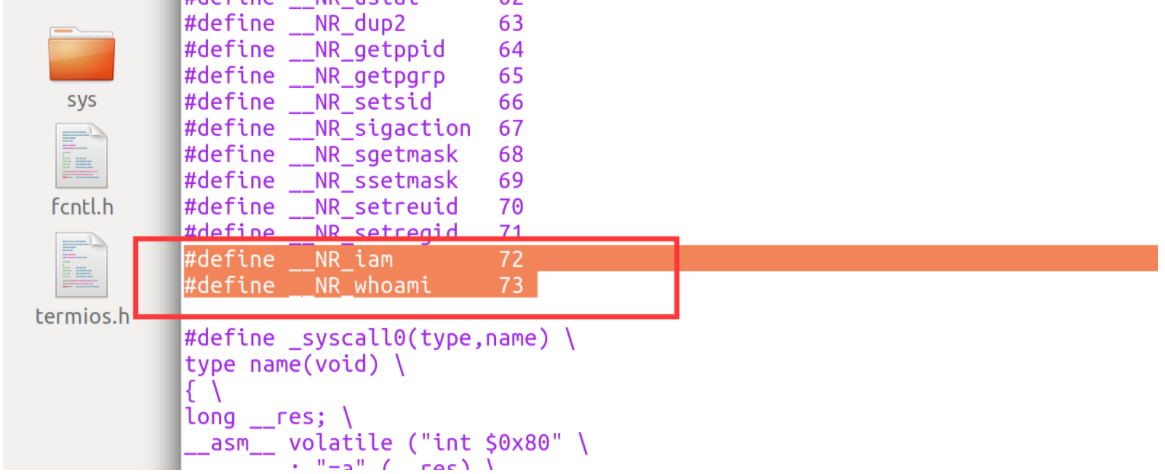
打开它并在宏定义出追加 __NR_whoami 和 __NR_iam两个宏,追加后的效果如下
2.添加用户空间接口函数
在挂载的文件系统内(在${OSLAB}/hdc/usr/root/目录下创建)任意位置新增以下两个文件
iam()函数文件
|
|
whoami()函数文件
|
|
新增完成后执行sudo umount hdc解除文件系统的挂载
3.修改system_call.s文件
在路径/oslab/linux-0.11/kernel下
修改系统调用总数
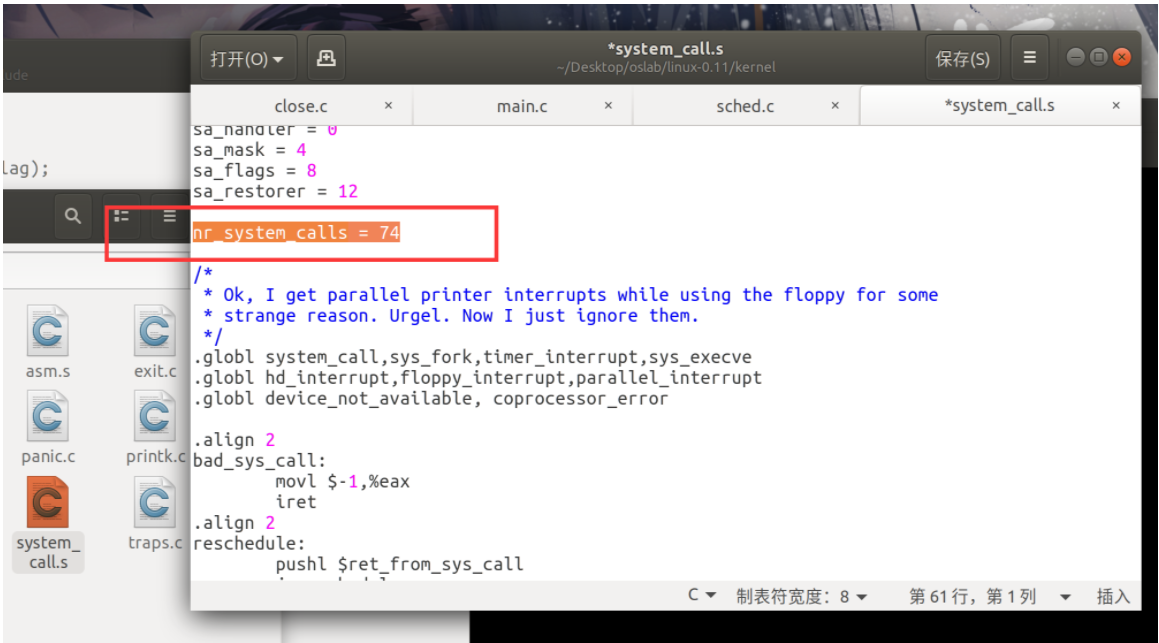
4.修改sys.h文件
路径:/oslab/linux-0.11/include/linux
在函数表内增加两个引用,位置需要一一对应。
|
|
效果如下
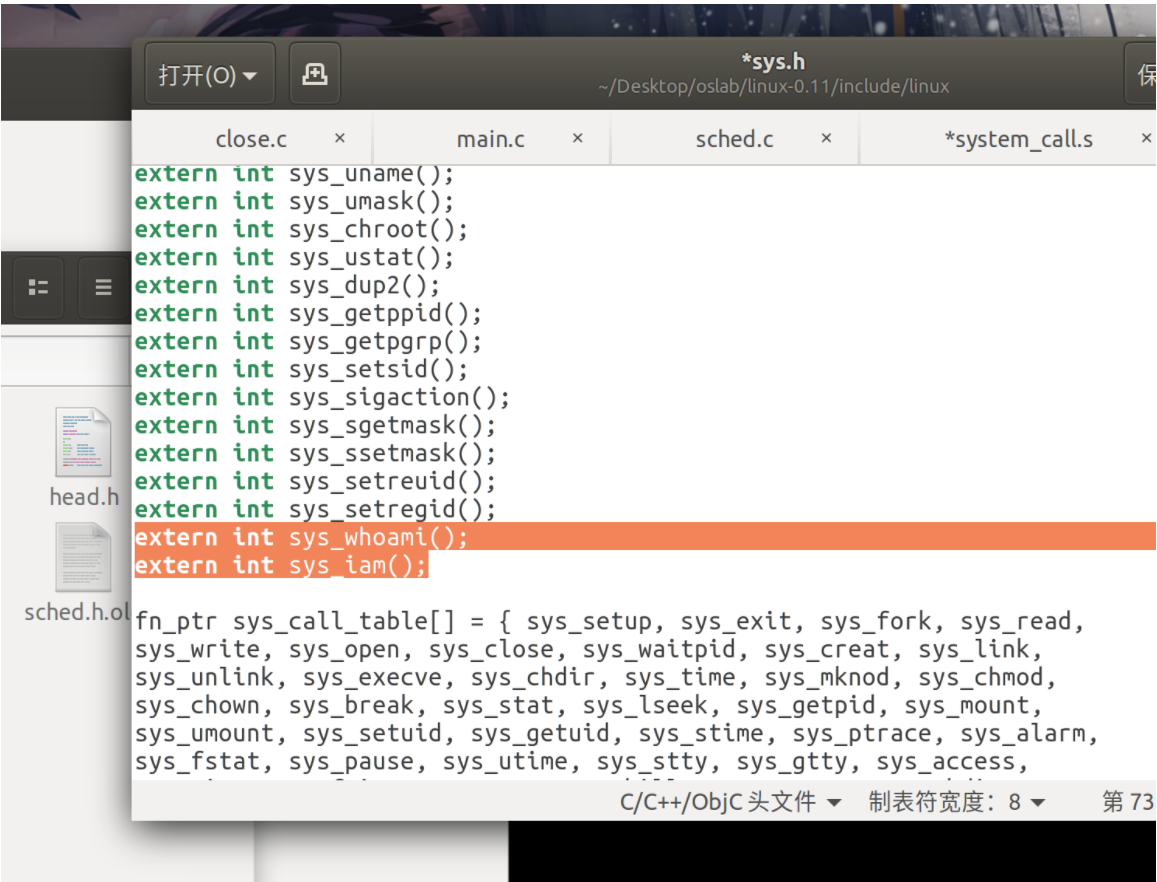
sys_call_table数组内加入sys_whoami和sys_iam,注意顺序一致
5.创建who.c文件
每个系统调用都有一个 sys_xxxxxx() 与之对应,所以增加的两个函数调用也需要有这种函数与其对应
|
|
|
|
将这个文件保存在kernel文件夹下
6.修改Makefile文件
kernel/Makefile
找到如下内容
|
|
并更改为
|
|
找到如下内容
|
|
并更改为
|
|
修改完成后执行make命令即可。
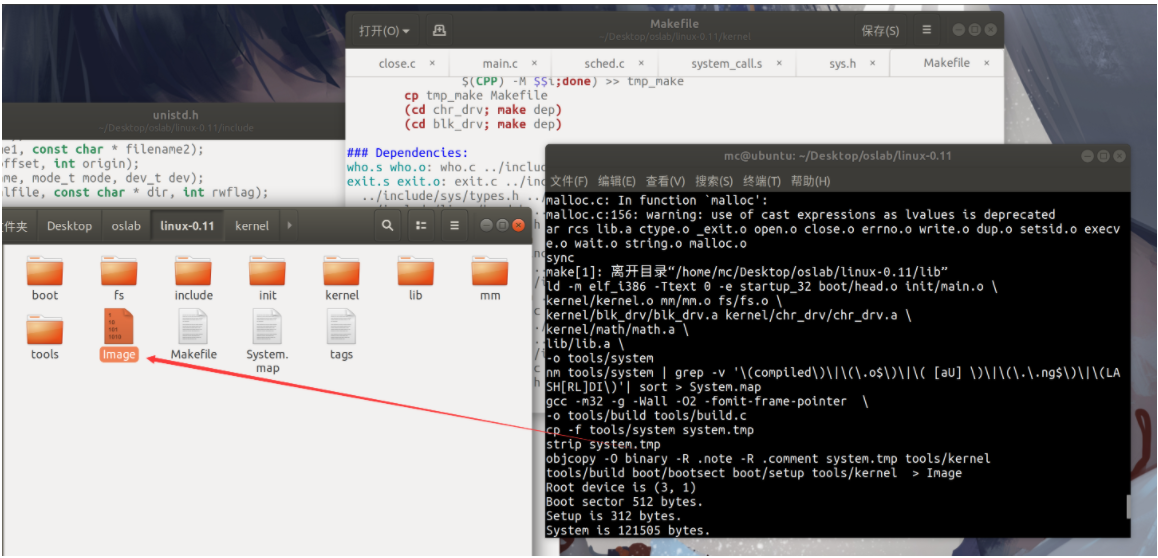
7.运行更改后的系统
在oslab根目录内输入**./run**命令进行调试 然后进入iam.c和whoami.c的目录执行下列命令
|
|
遇到的问题
编译出错:
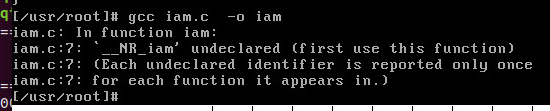
问题出在头文件上面!!!
==在 0.11 环境下编译 C 程序,包含的头文件都在 /usr/include 目录下。==
该目录下的
unistd.h是标准头文件(它和 0.11 源码树中的unistd.h==并不是同一个文件==,虽然内容可能相同),没有__NR_whoami和__NR_iam两个宏,需要手工加上它们,也可以直接从修改过的 0.11 源码树中拷贝新的 unistd.h 过来。
在内核中的代码包含的头文件是在/usr/include 下找的,但是我没有在该目录下的unistd.h修改,所以一直提示找不到头文件中定义的函数
把linux-0.11/include/unistd.h拷贝到hdc/usr/include下
再次编译,就没报错了(编译完后要sync) 不然编译后的文件关掉后再打开就不见了
|
|
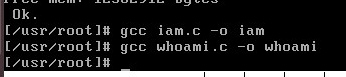
结果:
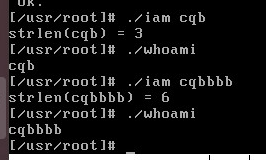
最后执行可执行文件iam和whoami进行测试 iam测试结果如下:
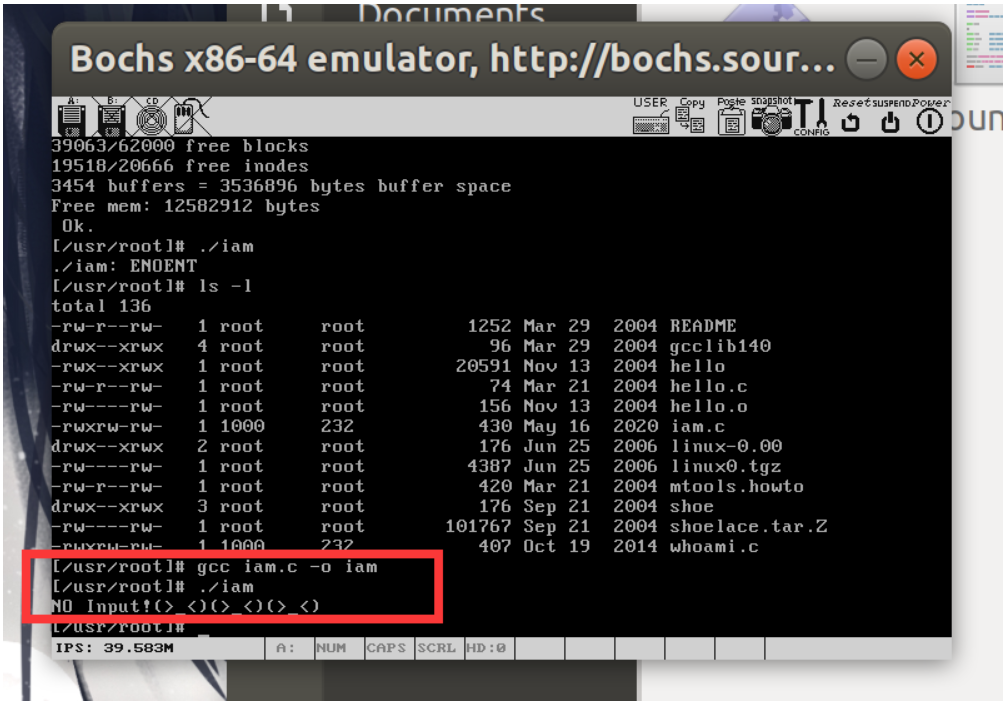
whoami测试结果如下:
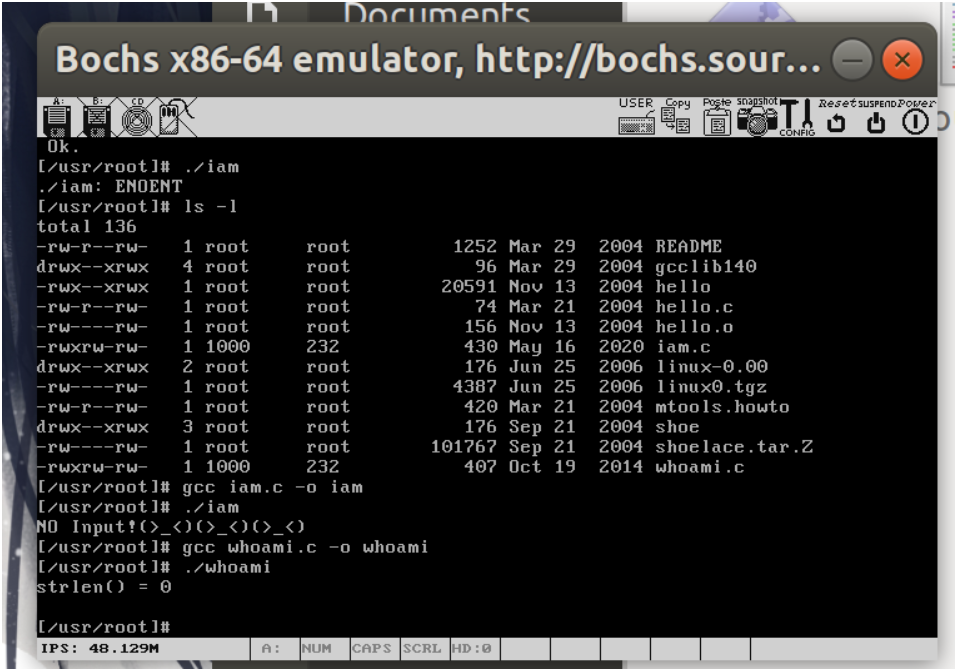
6. 实验报告
问题一
Linux-0.11的系统调用通过寄存器ebx、ecx、edx传递参数,最多能传递3个参数。 扩大传递参数的数量的方法:
- 增加传参所用的寄存器;
- 利用自定义的结构体辅助参数的传递(c语言结构体);
- 将寄存器拆分为高位和低位传递一直比较小的参数;
- 利用堆栈传递参数。
问题二
1.在include/unistd.h中定义宏__NR_foo,并添加供用户调用的函数声明void foo();
2.修改kernel/system_call.s中的nr_system_calls,增加新的系统调用;
3.在include/linux/sys.h中添加函数声明extern void sys_foo(),在系统调用入口表fn_ptr末端添加元素sys_foo;
4.添加kernel/foo.c文件,实现sys_foo()函数;
5.修改kernel/Makefile,在OBJS中加入foo.o,并添加生成foo.s、foo.o的依赖规则;
6.重新执行make命令,并进入挂载的文件系统内进行编译测试。